Publications
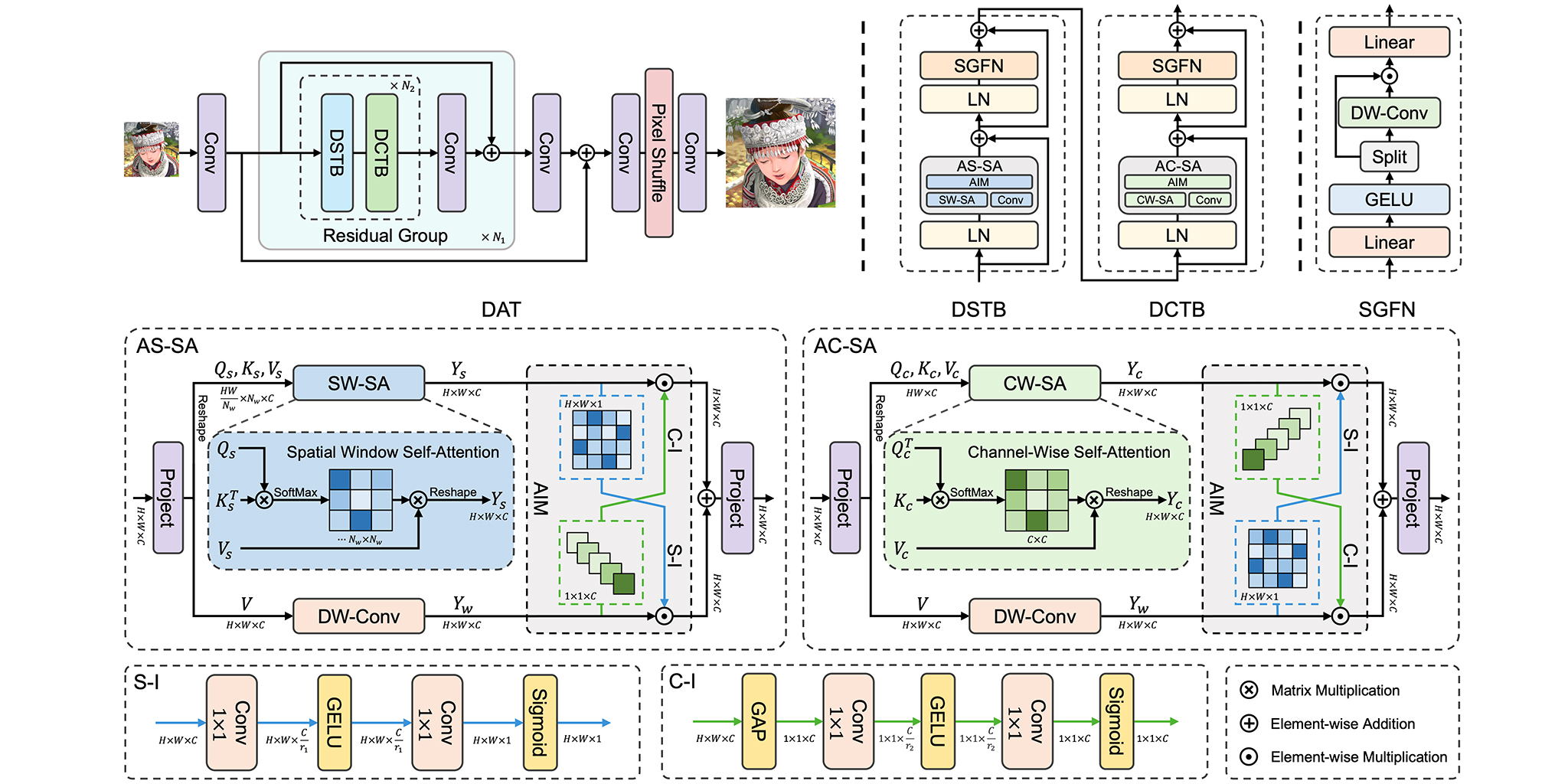
Dual Aggregation Transformer for Image Super-Resolution
ICCV 2023 A new image super-resolution model, dual aggregation Transformer (DAT), that aggregates spatial and channel features in the dual manner, achieves state-of-the-art performance.
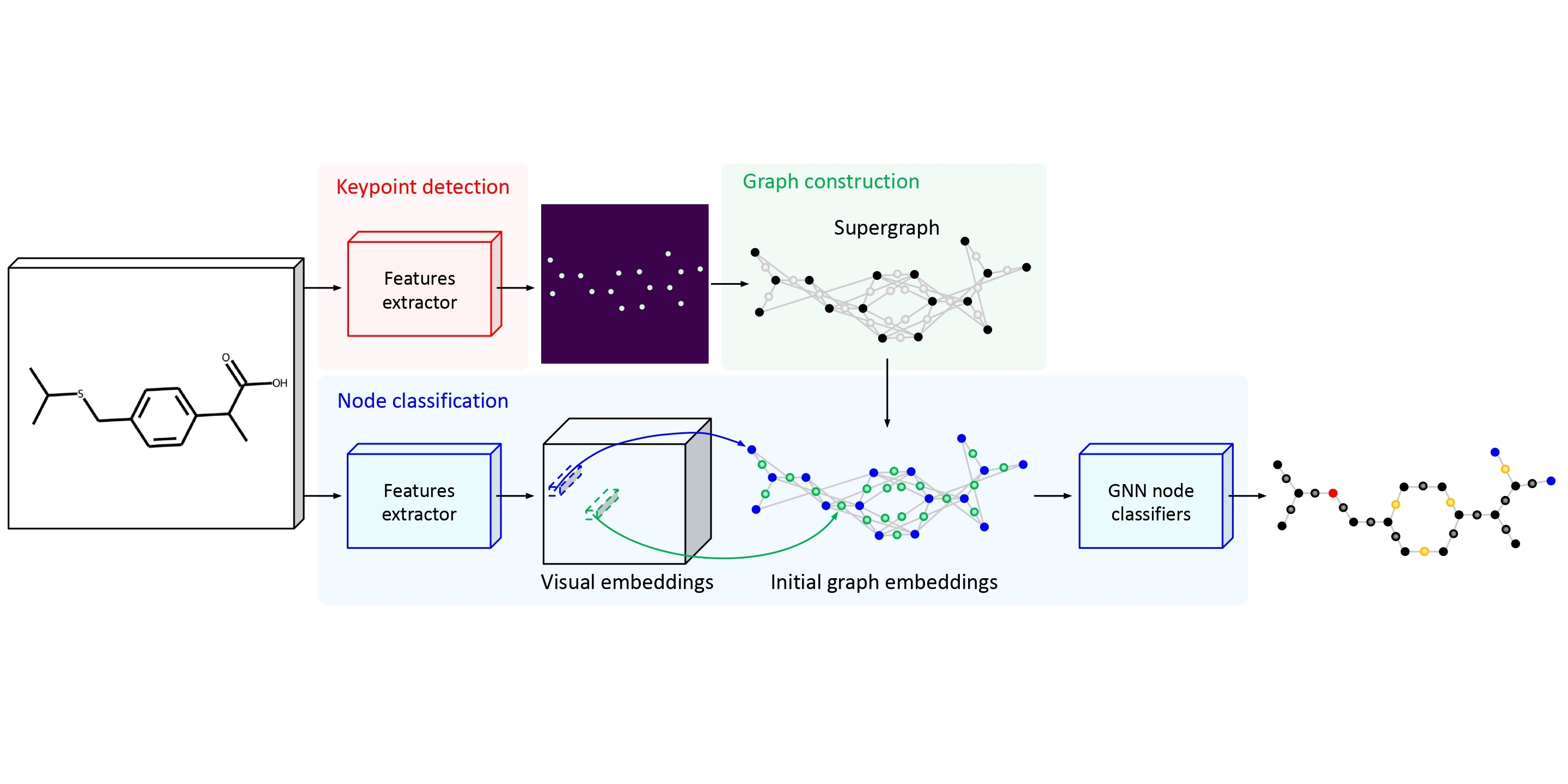
MolGrapher: Graph-based Visual Recognition of Chemical Structures
ICCV 2023 We propose a graph-based method for the recognition of chemical structure images.
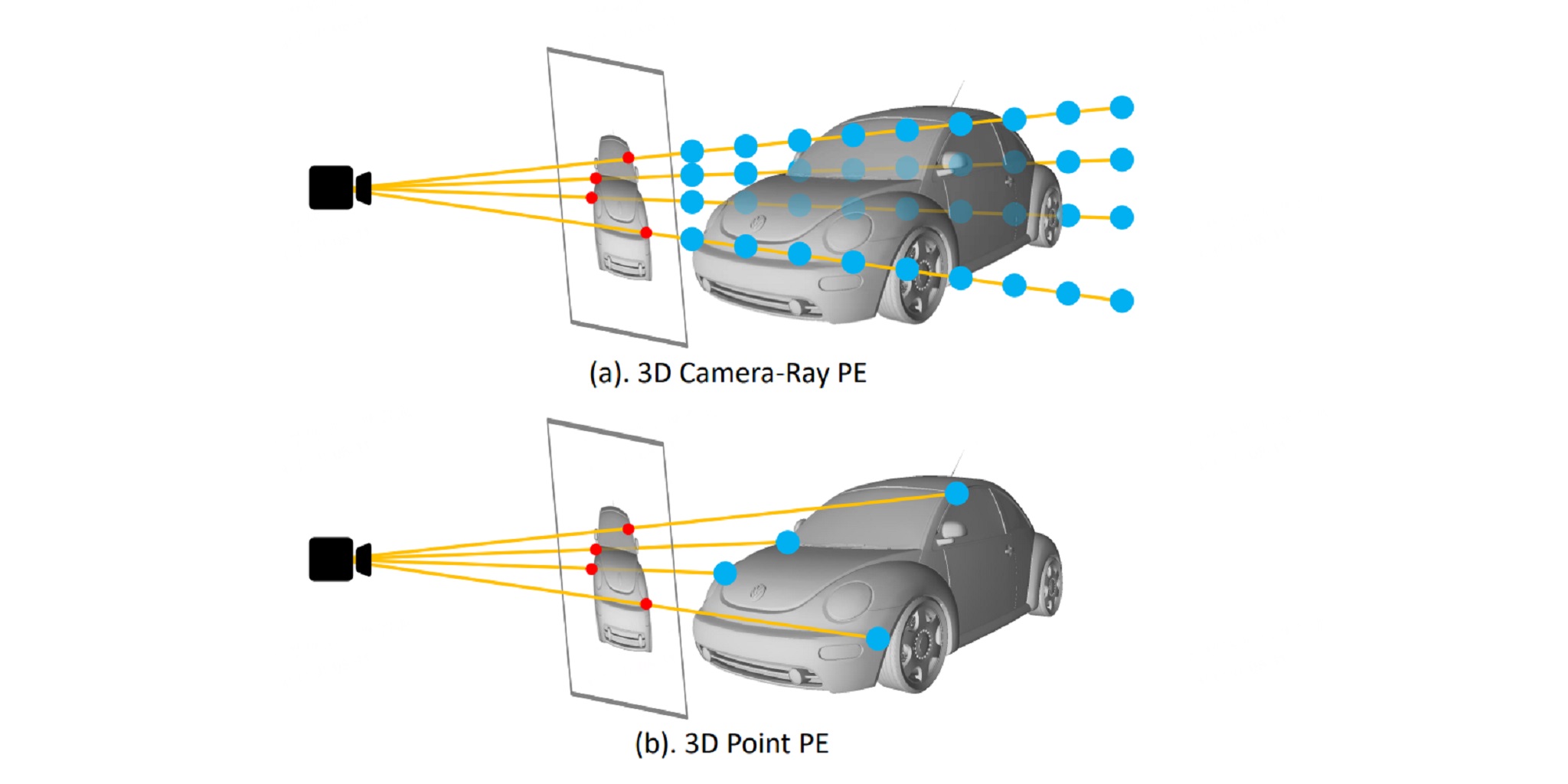
3DPPE: 3D Point Positional Encoding for Multi-Camera 3D Object Detection Transformers
ICCV 2023 We propose 3D point PE with depth prior to localize the 2D feature, and it unifies representation of positional encoding for both image feature and object query.

Learning Deep Sensorimotor Policies for Vision-Based Autonomous Drone Racing
IROS 2023 This paper presents a method for learning deep sensorimotor policies for vision-based drone racing with Learning by Cheating, which achieves robust performance against visual disturbances by learning well-aligned image embeddings using contrastive learning and data augmentation.
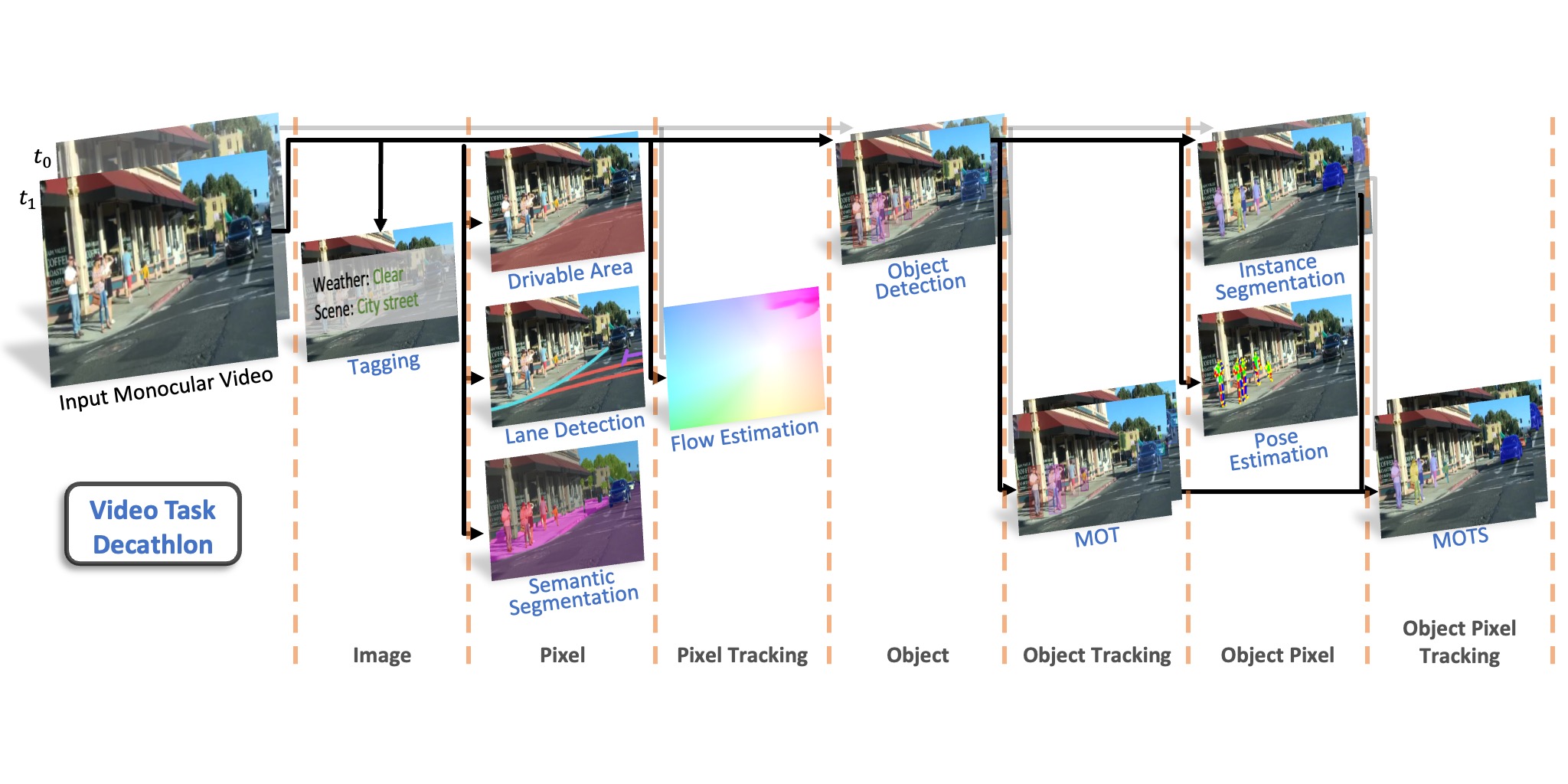
Video Task Decathlon: Unifying Image and Video Tasks in Autonomous Driving
ICCV 2023 VTD is a promising new direction for exploring the unification of perception tasks in autonomous driving.
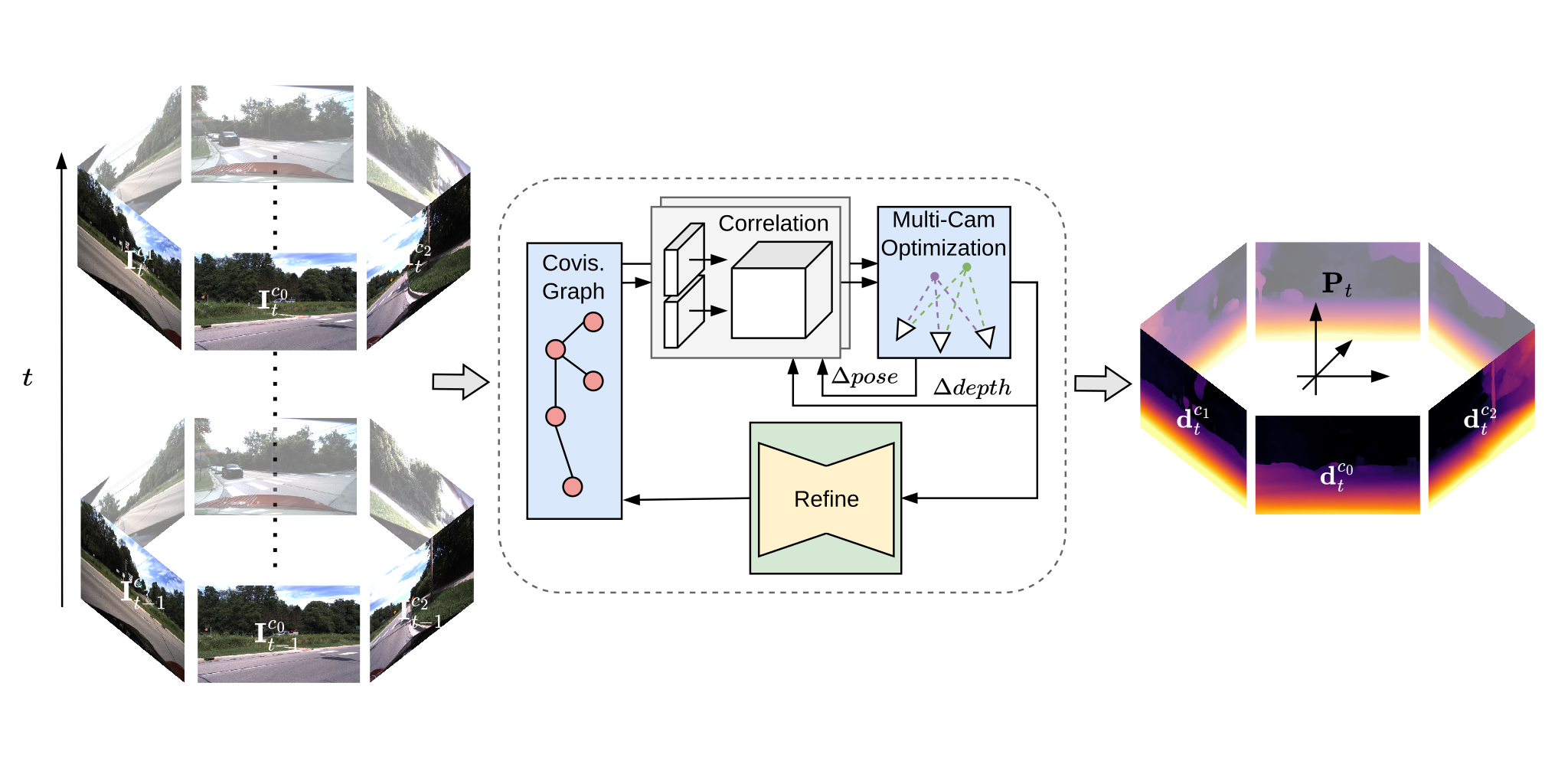
R3D3: Dense 3D Reconstruction of Dynamic Scenes from Multiple Cameras
ICCV 2023 We propose a method for dense 3D reconstruction and ego-motion estimation from multi-camera input in dynamic environments.
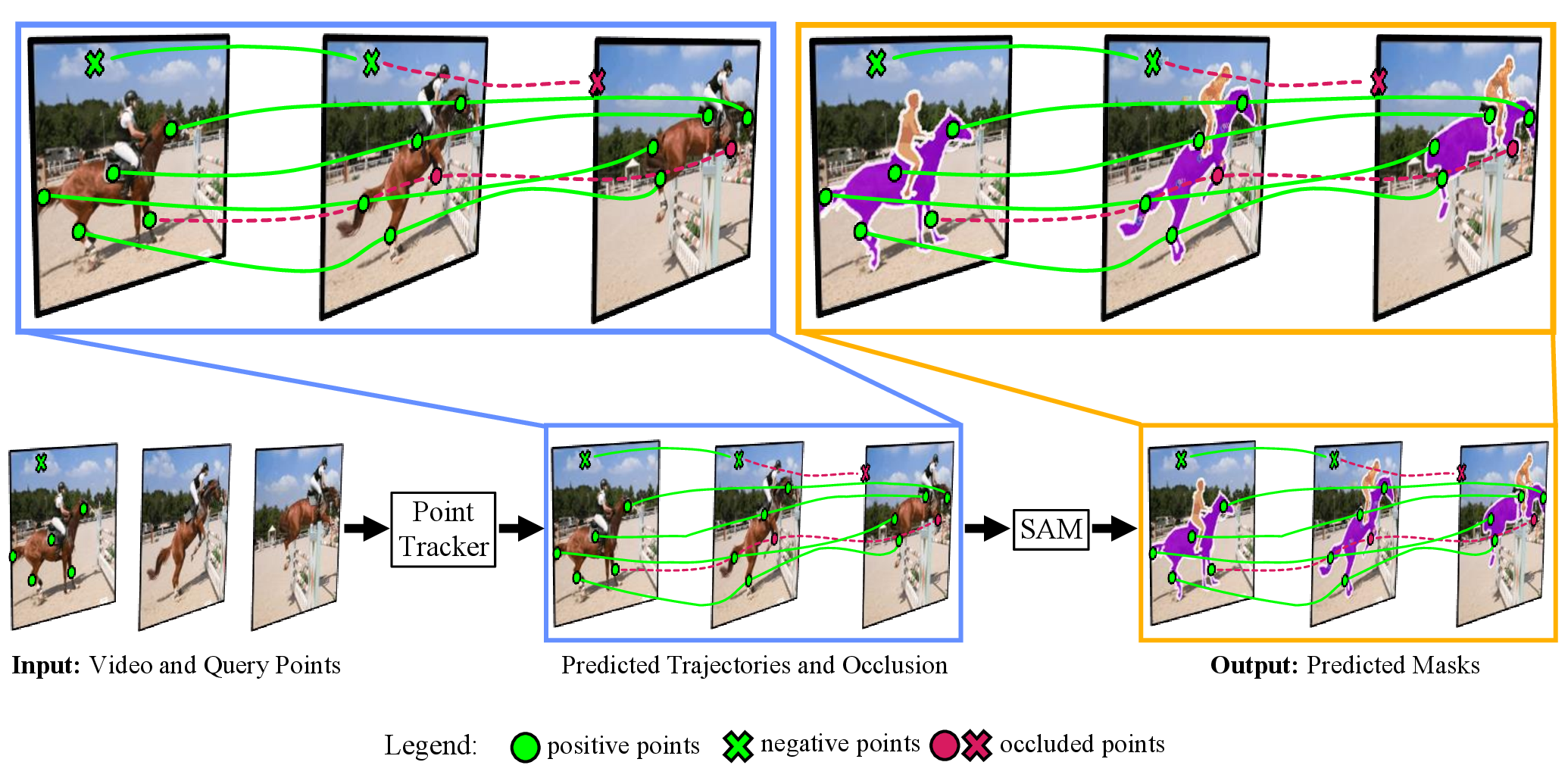
Segment Anything Meets Point Tracking
arXiv 2023 Extending SAM to video segmentation with point-based tracking to demonstrate strong zero-shot performance across popular video segmentation benchmarks.

OVTrack: Open-Vocabulary Multiple Object Tracking
CVPR 2023 We introduce the first open-vocabulary multiple object tracker OVTrack trained from only static images and an evaluation benchmark.
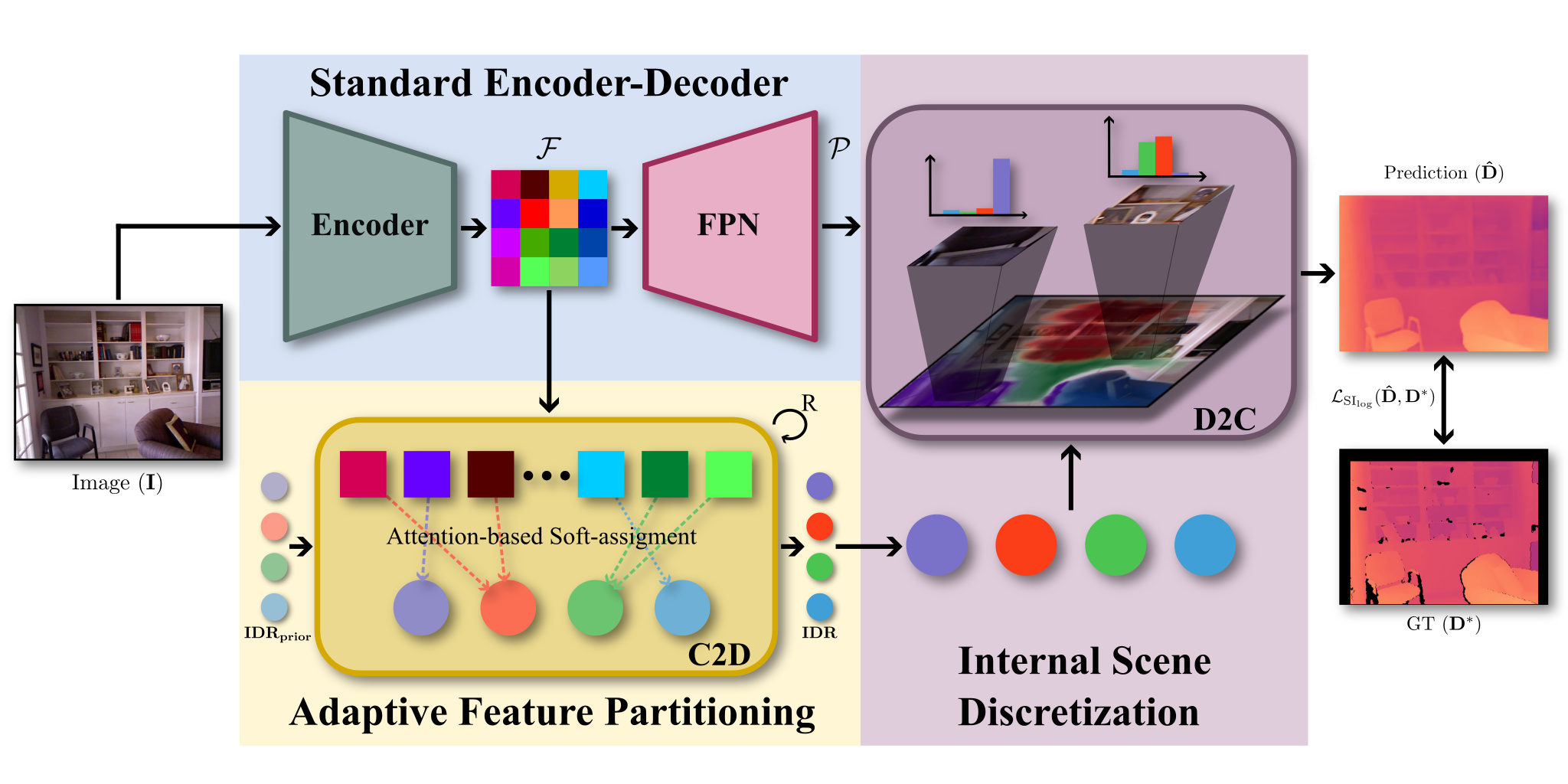
iDisc: Internal Discretization for Monocular Depth Estimation
CVPR 2023 We propose a monocular depth estimation method which represents internally the scene as a finite set of concepts via a continuous-discrete-continuous bottleneck
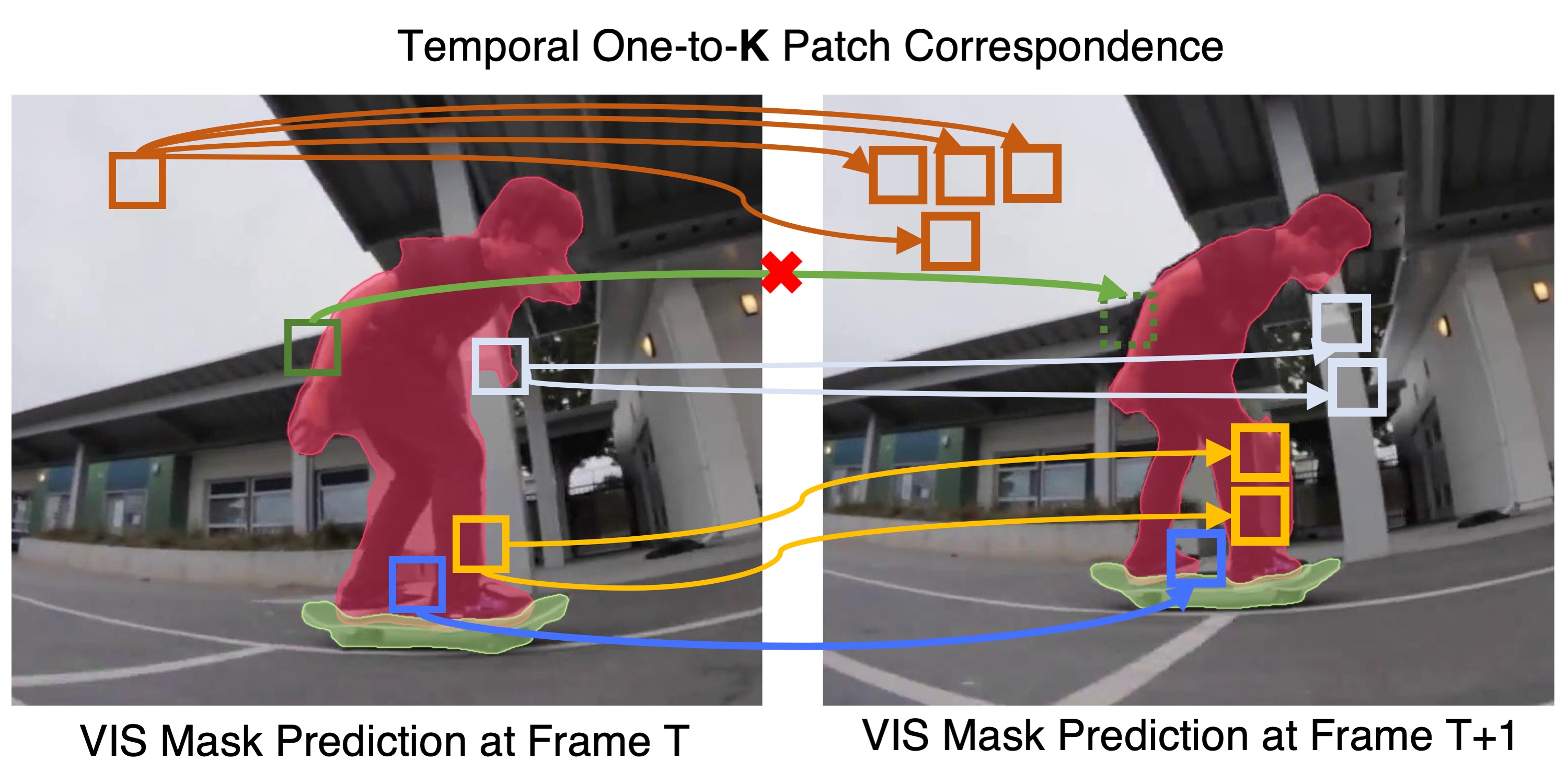
Mask-Free Video Instance Segmentation
CVPR 2023 We remove video and image mask annptation necessity for training highly accurate VIS models.
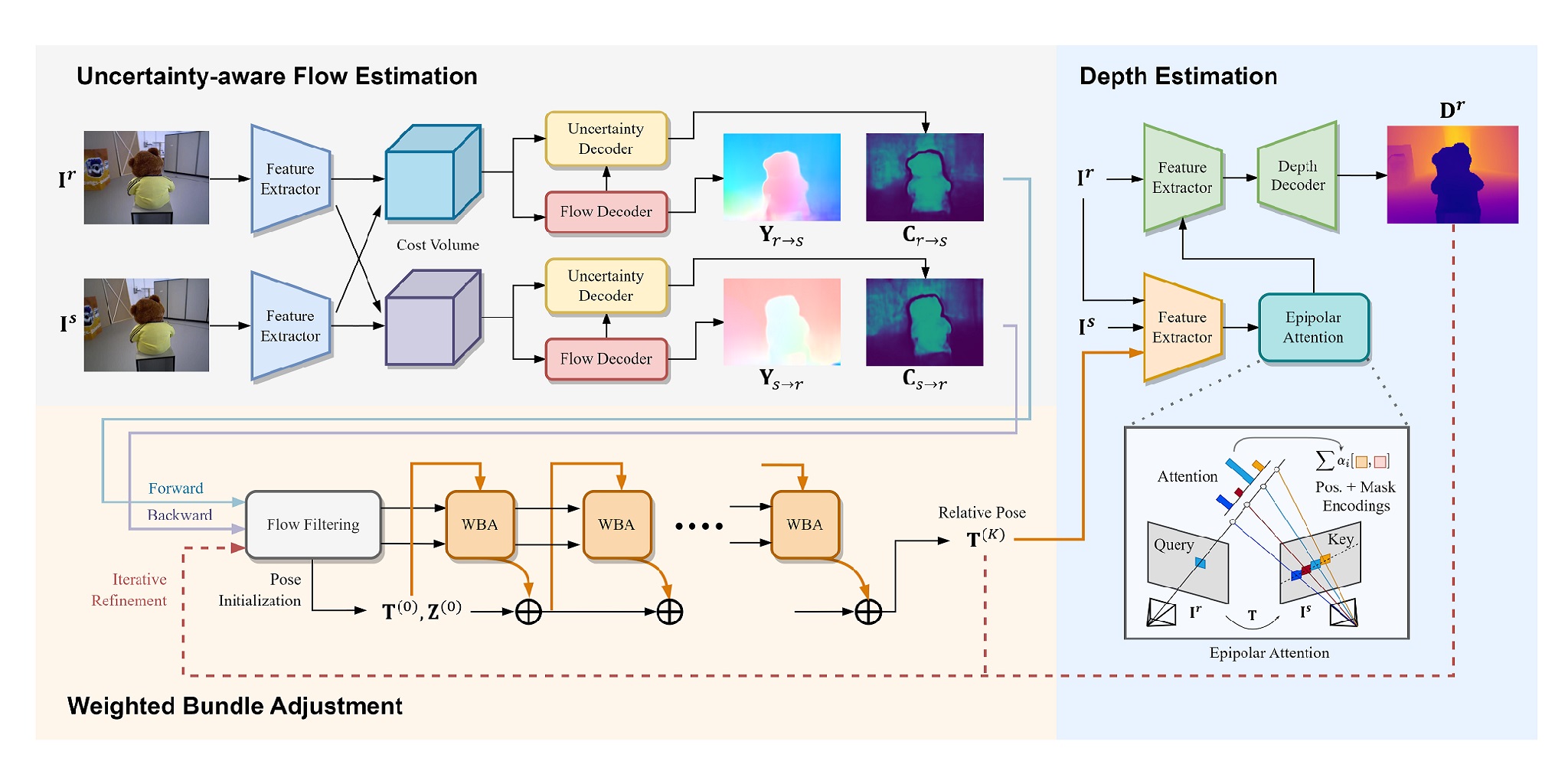
Uncertainty-Driven Dense Two-View Structure from Motion
RA-L 2023 We introduce an uncertainty-driven Dense Two-View SfM pipeline.
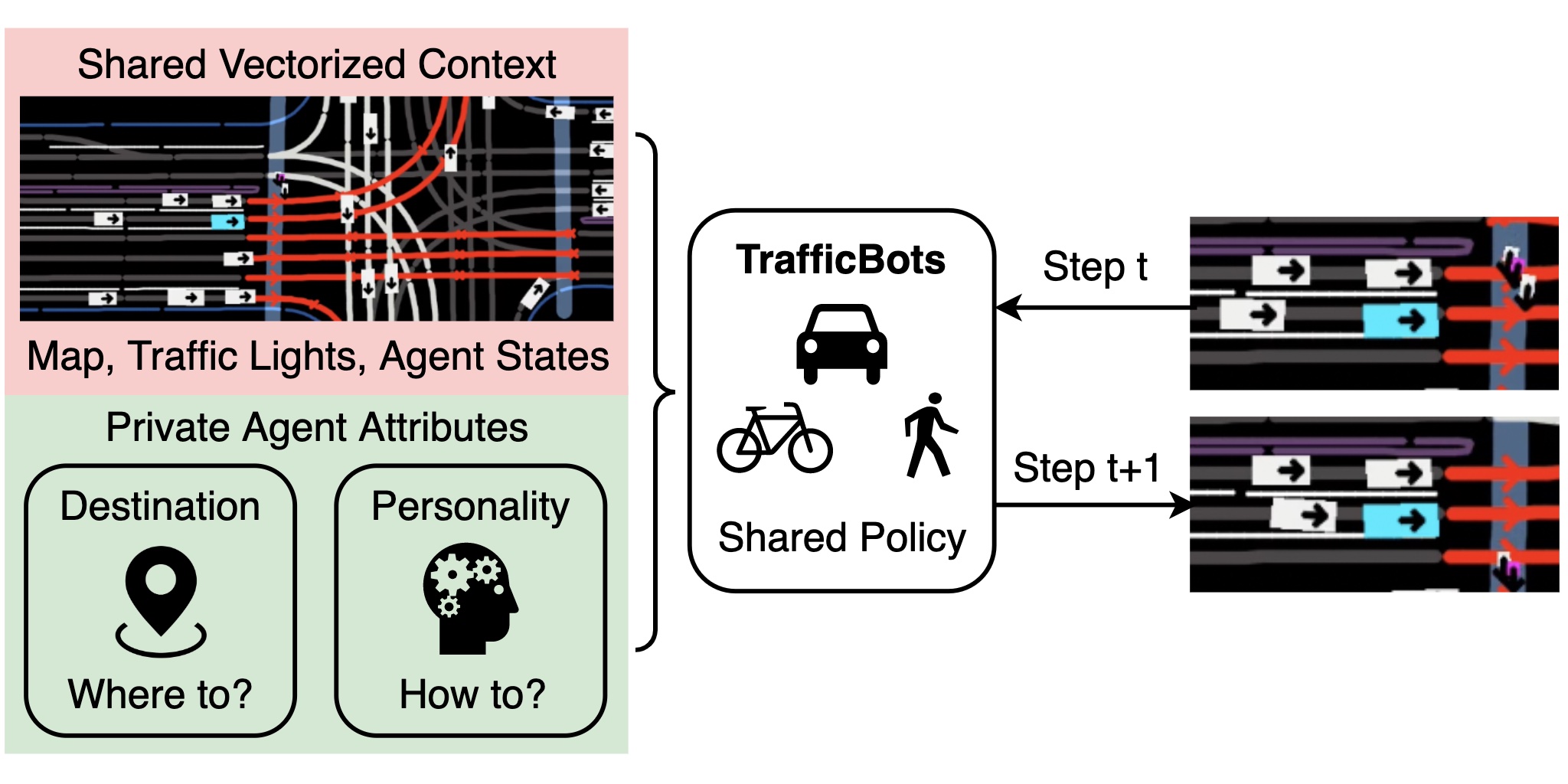
TrafficBots: Towards World Models for Autonomous Driving Simulation and Motion Prediction
ICRA 2023 We present TrafficBots, a multi-agent policy built upon motion prediction and end-to-end driving.
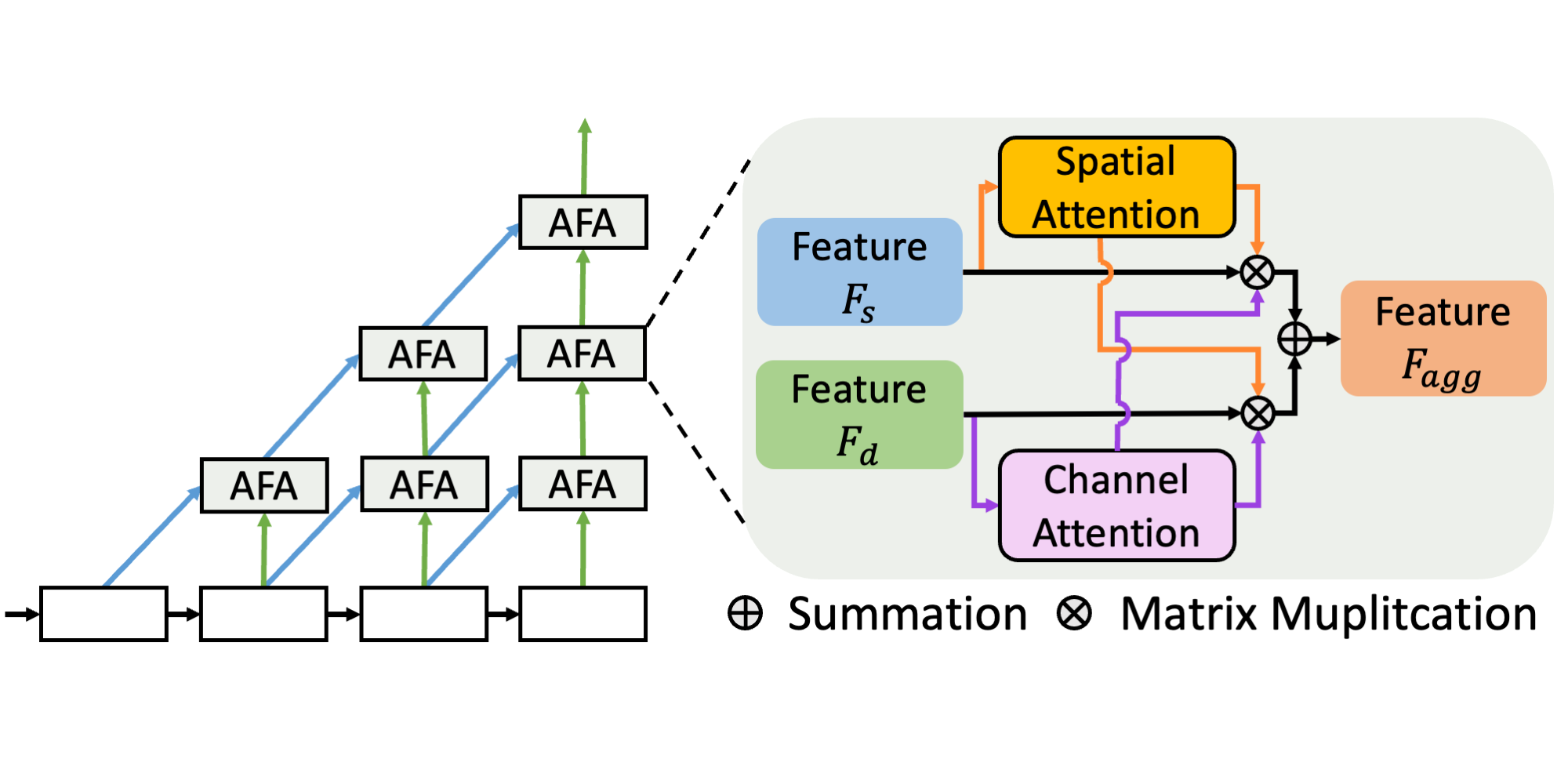
Dense Prediction with Attentive Feature Aggregation
WACV 2023 We propose Attentive Feature Aggregation (AFA) to exploit both spatial and channel information for semantic segmentation and boundary detection.
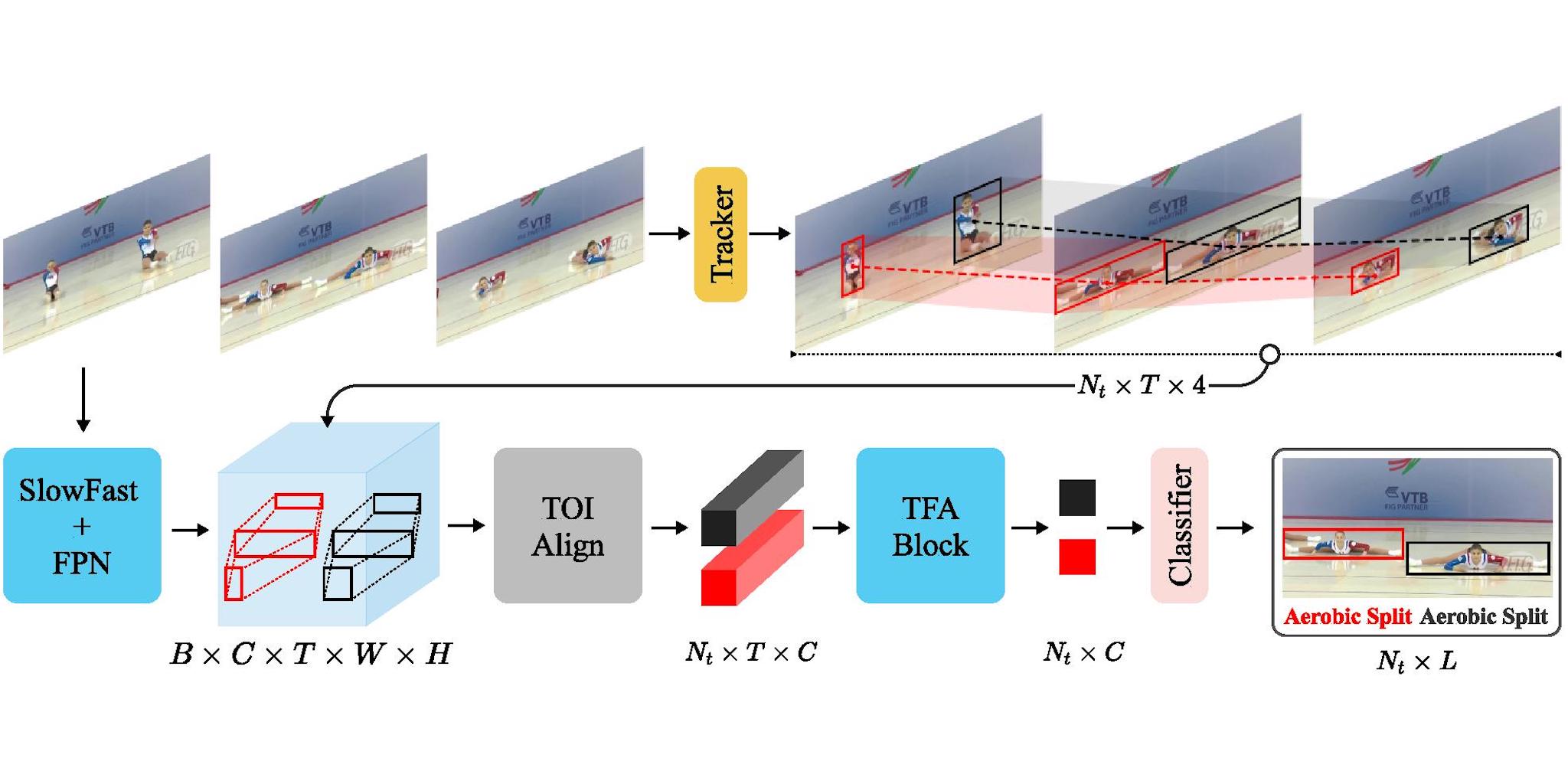
Spatio-Temporal Action Detection Under Large Motion
WACV 2023 We propose to enhance actor feature representation under large motion by tracking actors and performing temporal feature aggregation along the respective tracks.
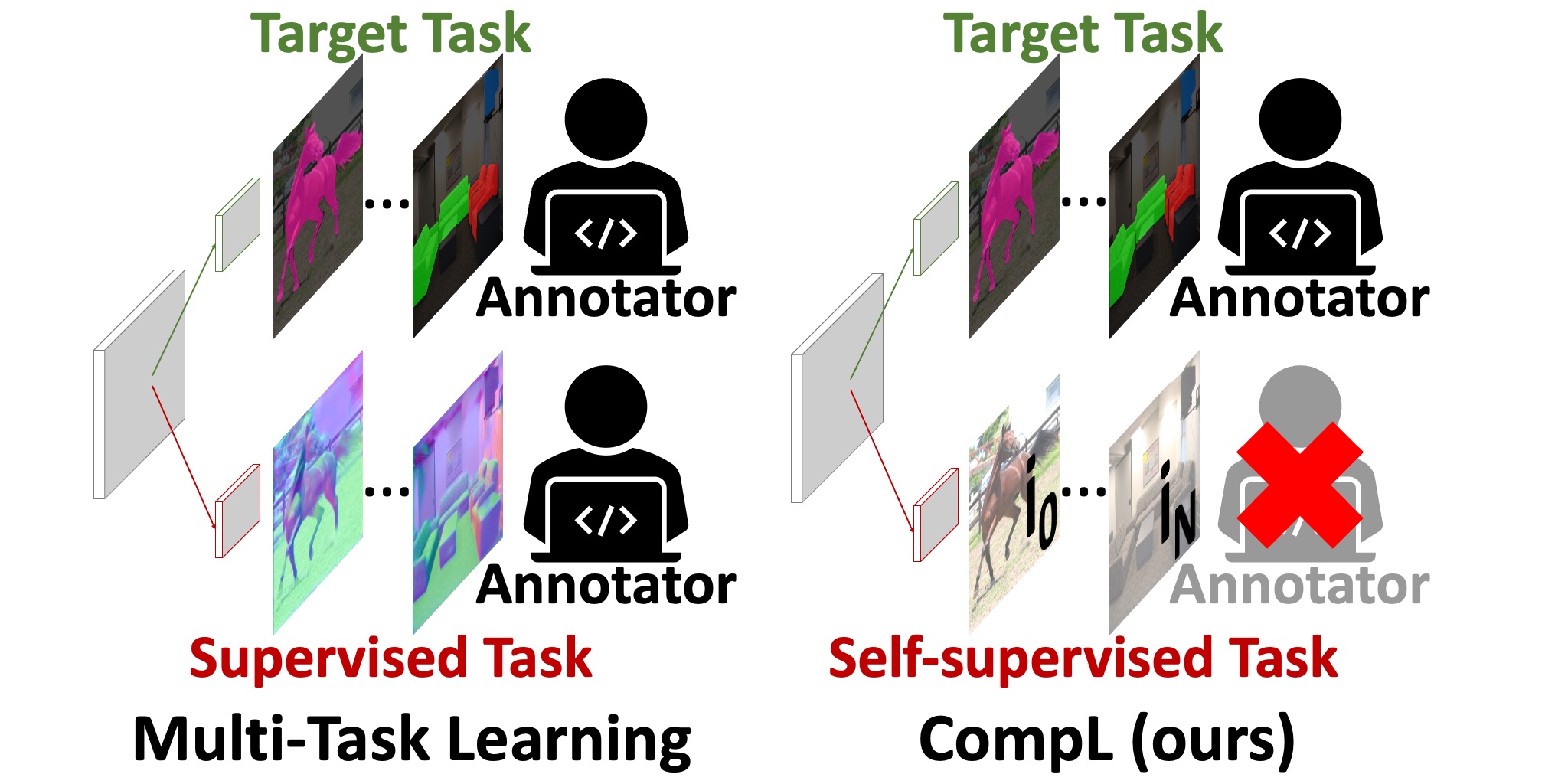
Composite Learning for Robust and Effective Dense Predictions
WACV 2023 We find that jointly training a dense prediction task with a self-supervised task can consistently improve the performance of the target task.
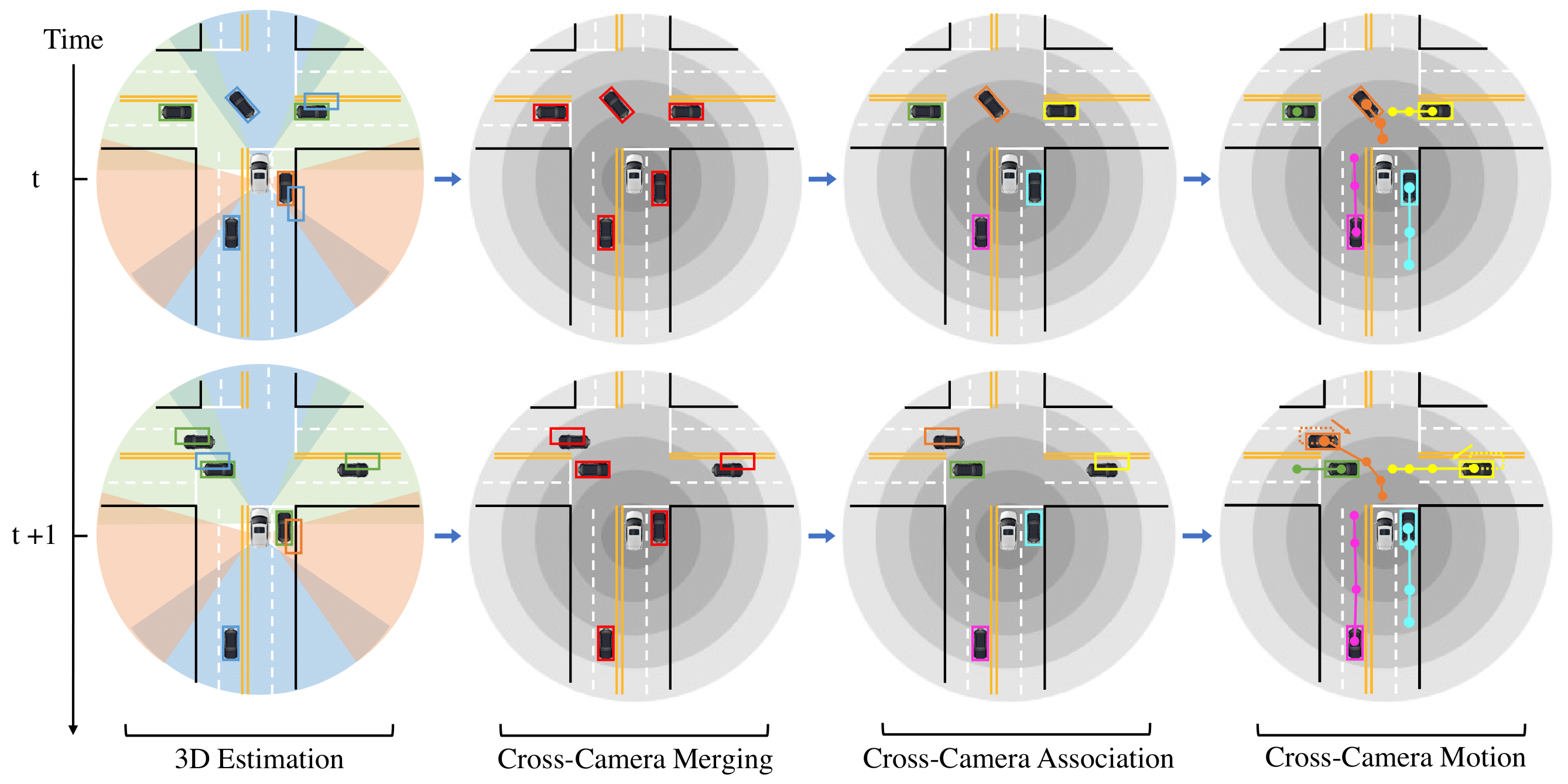
CC-3DT: Panoramic 3D Object Tracking via Cross-Camera Fusion
CoRL 2022 We propose a method for panoramic 3D object tracking, called CC-3DT, that associates and models object trajectories both temporally and across views.

Uncertainty Guided Policy for Active Robotic 3D Reconstruction using Neural Radiance Fields
RA-L 2022 This paper introduces a ray-based volumetric uncertainty estimator, which computes the entropy of the weight distribution of the color samples along each ray of the object’s implicit neural representation.
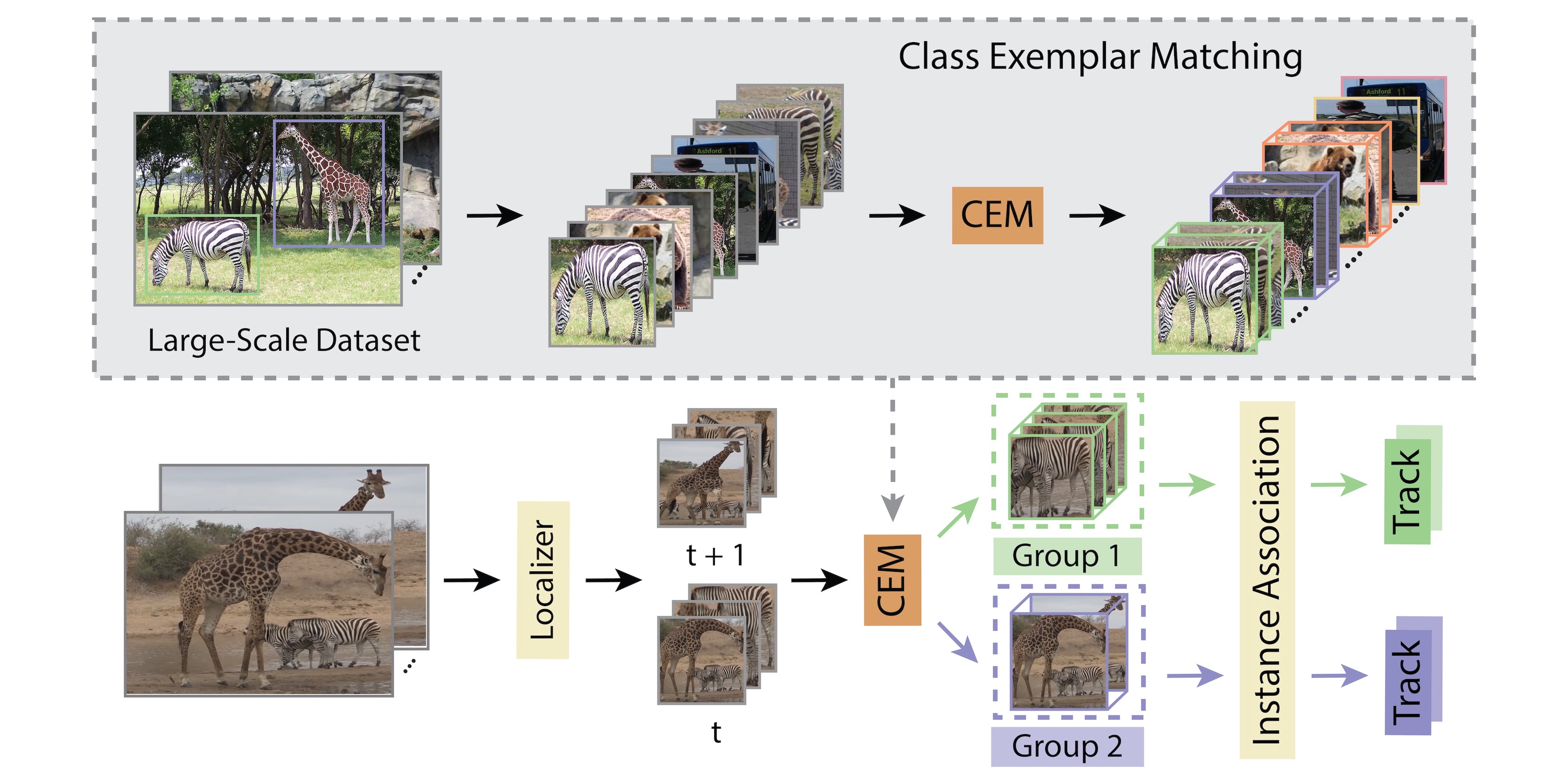
Tracking Every Thing in the Wild
ECCV 2022 We introduce a new metric, Track Every Thing Accuracy (TETA), and a Track Every Thing tracker (TETer), which performs association using Class Exemplar Matching (CEM).
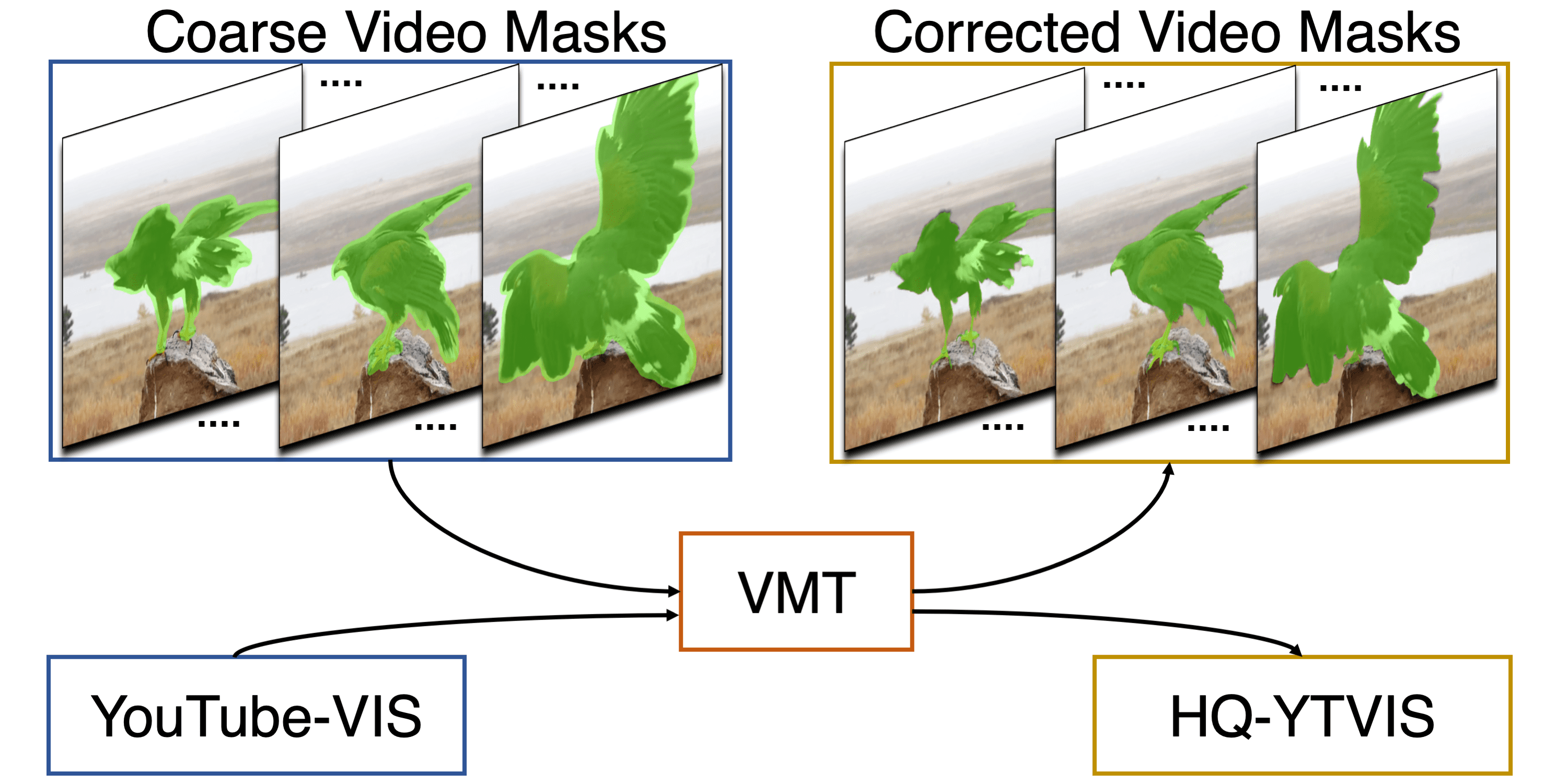
Video Mask Transfiner for High-Quality Video Instance Segmentation
ECCV 2022 We propose Video Mask Transfiner (VMT) method, capable of leveraging fine-grained high-resolution features thanks to a highly efficient video transformer structure.
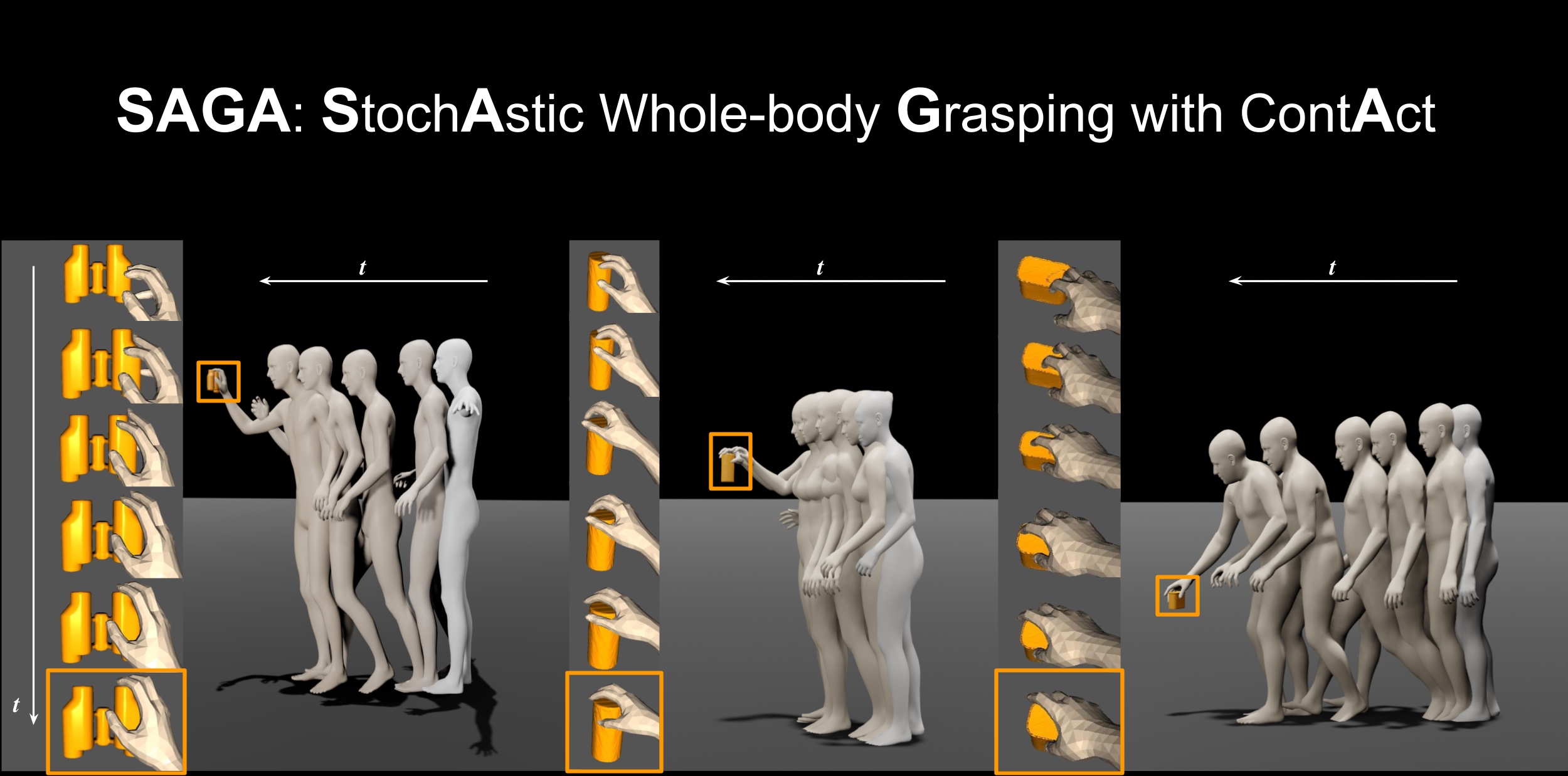
SAGA: Stochastic Whole-Body Grasping with Contact
ECCV 2022 We propose SAGA (StochAstic whole-body Grasping with contAct).

Learning Online Multi-Sensor Depth Fusion
ECCV 2022 Our method fuses multi-sensor depth streams regardless of time synchronization and calibration and generalizes well with little training data.
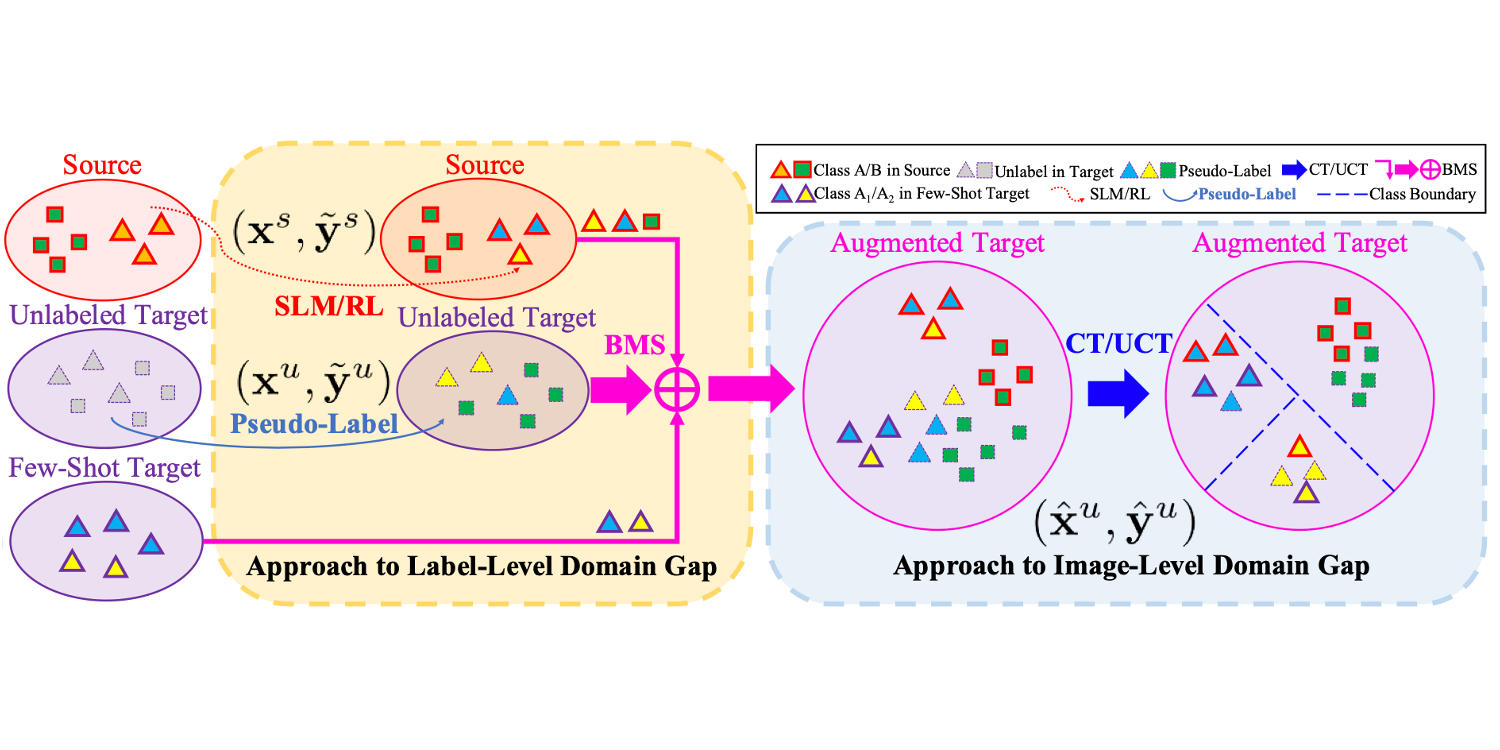
TACS: Taxonomy Adaptive Cross-Domain Semantic Segmentation
ECCV 2022 We introduce the more general taxonomy adaptive cross-domain semantic segmentation (TACS) problem, allowing for inconsistent taxonomies between the two domains.
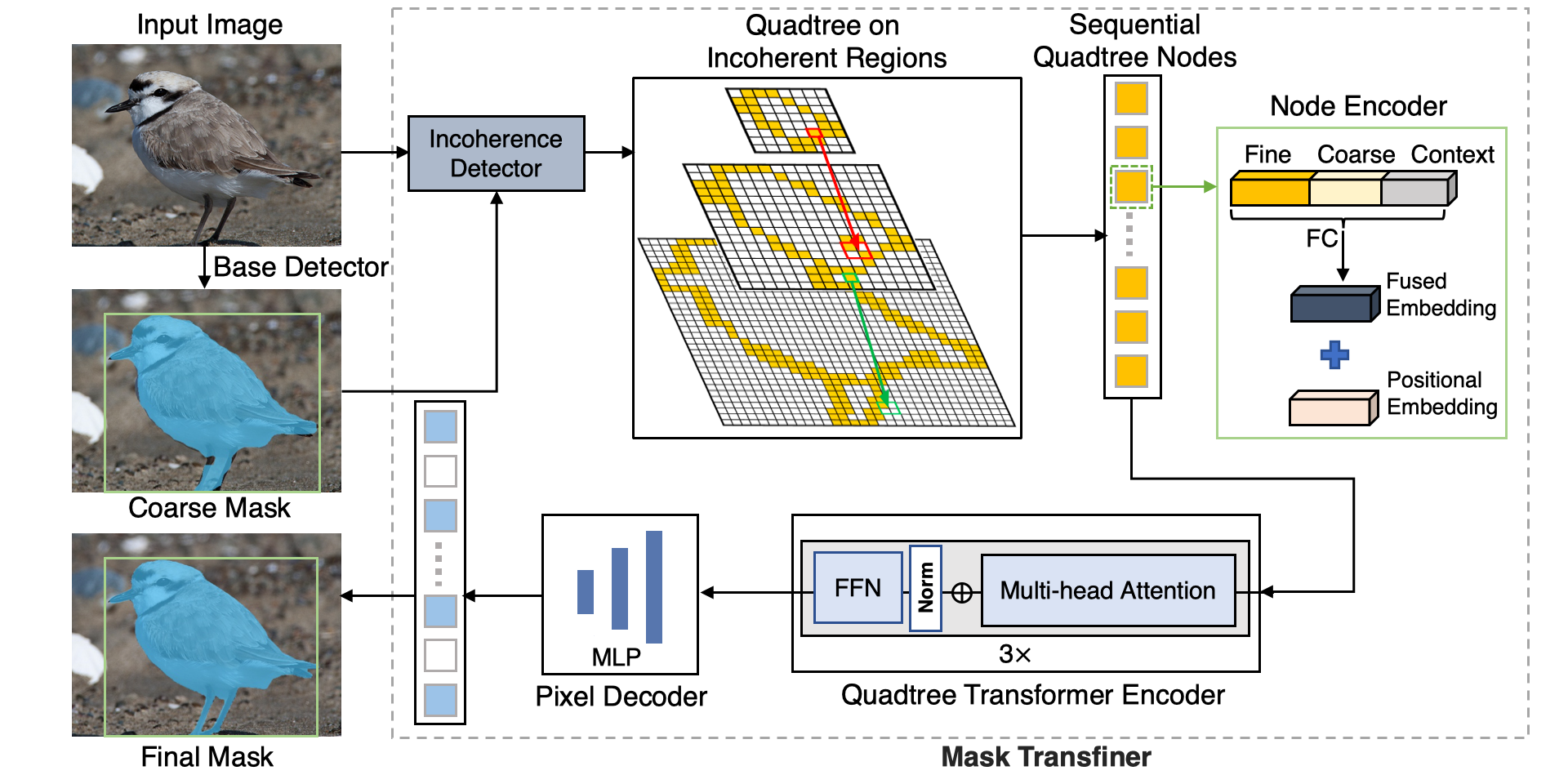
Mask Transfiner for High-Quality Instance Segmentation
CVPR 2022 we present Mask Transfiner for high-quality and efficient instance segmentation, which predicts highly accurate instance masks at a low computational cost using quadtree transformer.

SHIFT: A Synthetic Driving Dataset for Continuous Multi-Task Domain Adaptation
CVPR 2022 We introduce the largest synthetic dataset for autonomous driving to study continuous domain adaptation and multi-task perception.