Abstract
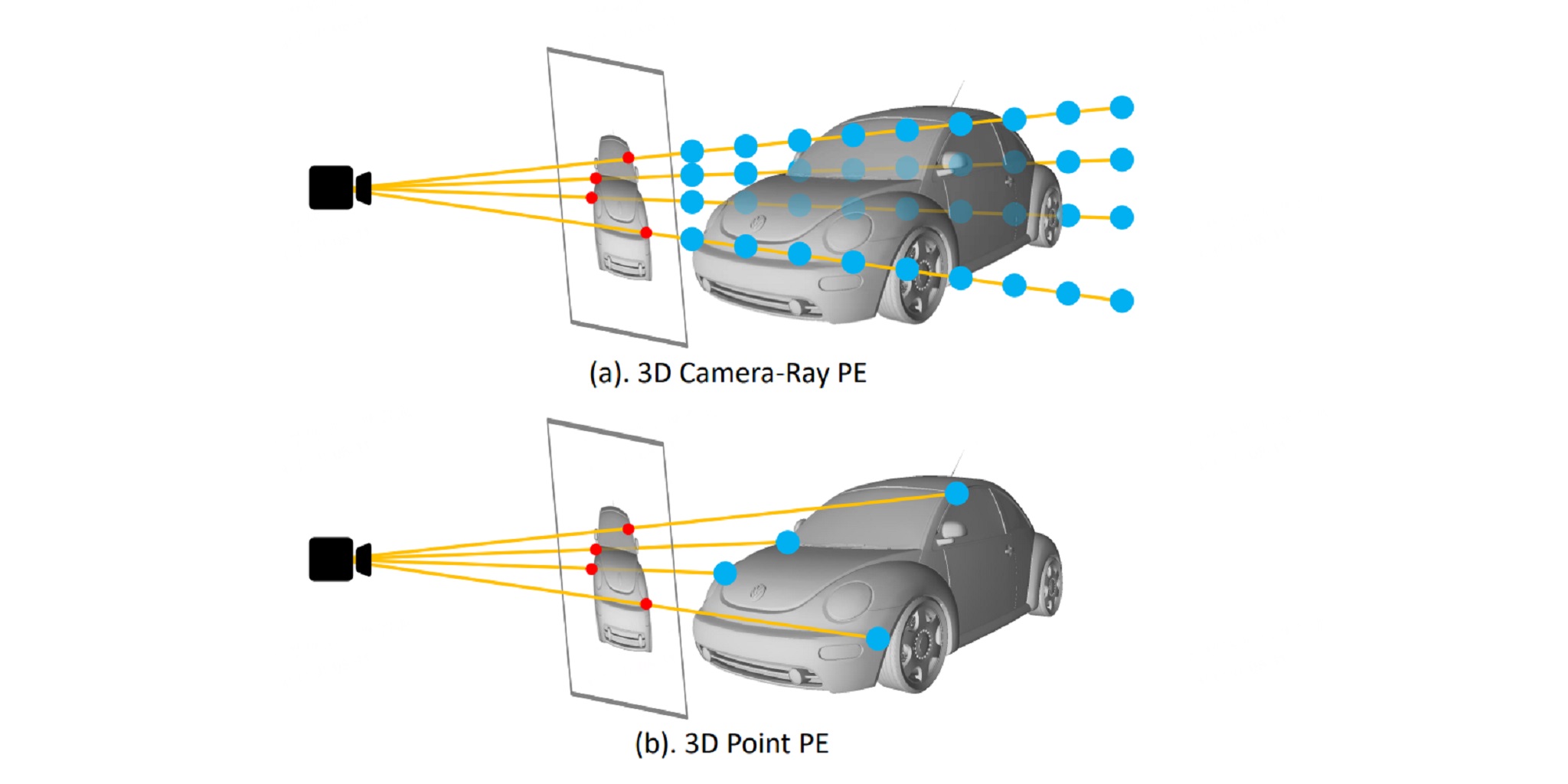
Transformer-based methods have swept the benchmarks on 2D and 3D detection on images. Because tokenization before the attention mechanism drops the spatial information, positional encoding becomes critical for those methods. Recent works found that encodings based on samples of the 3D viewing rays can significantly improve the quality of multi-camera 3D object detection. We hypothesize that 3D point locations can provide more information than rays. Therefore, we introduce 3D point positional encoding, 3DPPE, to the 3D detection Transformer decoder. Although 3D measurements are not available at the inference time of monocular 3D object detection, 3DPPE uses predicted depth to approximate the real point positions. Our hybriddepth module combines direct and categorical depth to estimate the refined depth of each pixel. Despite the approximation, 3DPPE achieves 46.0 mAP and 51.4 NDS on the competitive nuScenes dataset, significantly outperforming encodings based on ray samples.
Paper
 | Changyong Shu, Jiajun Deng, Fisher Yu, Yifan Liu 3DPPE: 3D Point Positional Encoding for Multi-Camera 3D Object Detection Transformers ICCV 2023 |
Code

github.com/drilistbox/3DPPE
Citation
@inproceedings{shu20233DPPE,
title={3DPPE: 3D Point Positional Encoding for Multi-Camera 3D Object Detection Transformers},
author={Shu, Changyong and Deng, Jiajun and Yu, Fisher and Liu, Yifan},
journal={International Conference on Computer Vision (ICCV)},
year={2023}
}