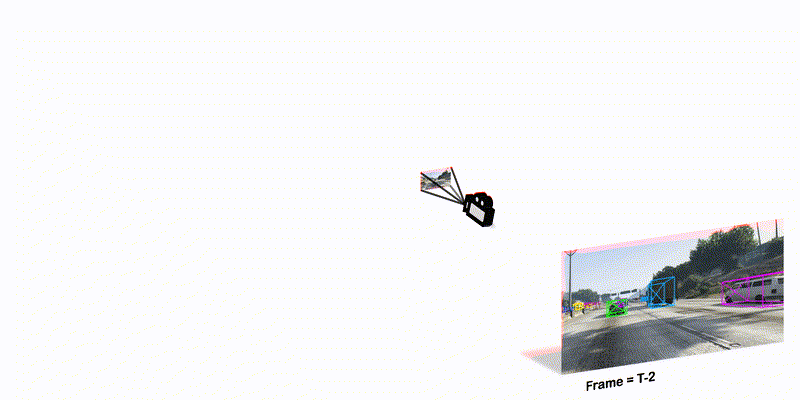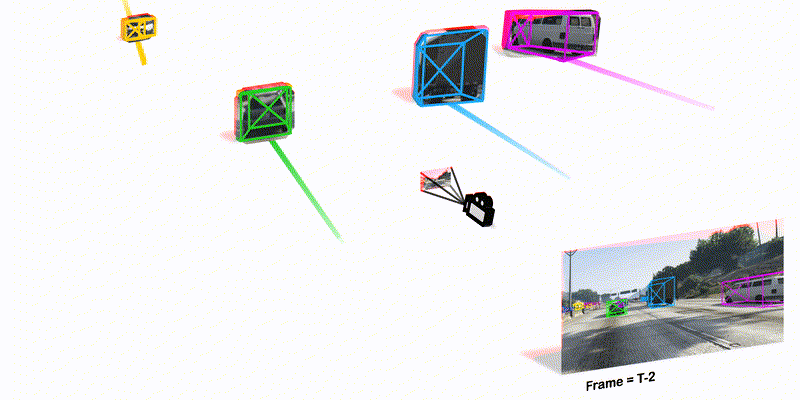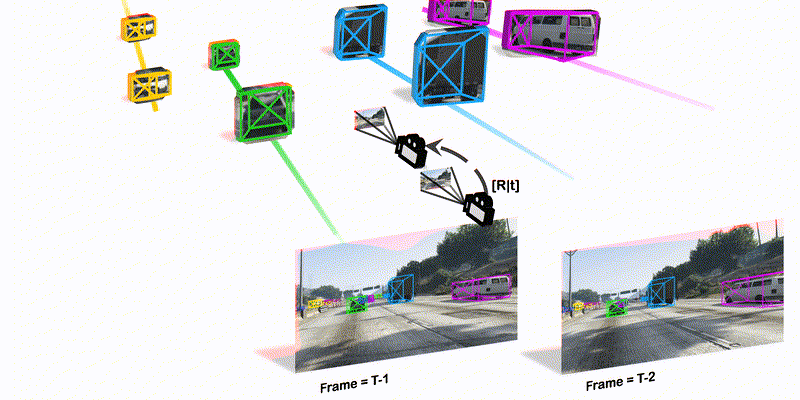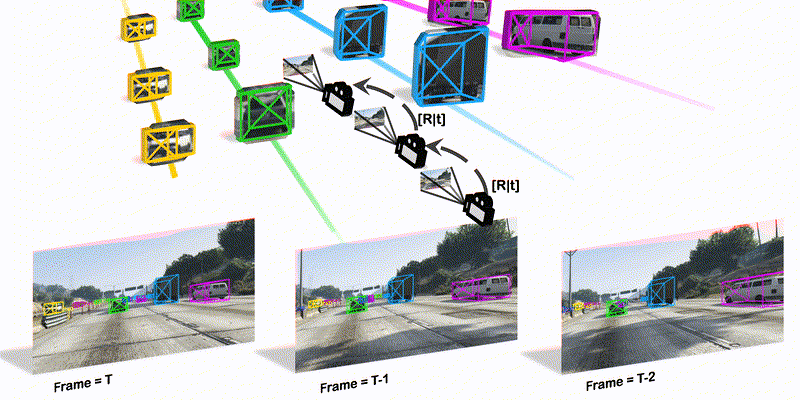
Abstract
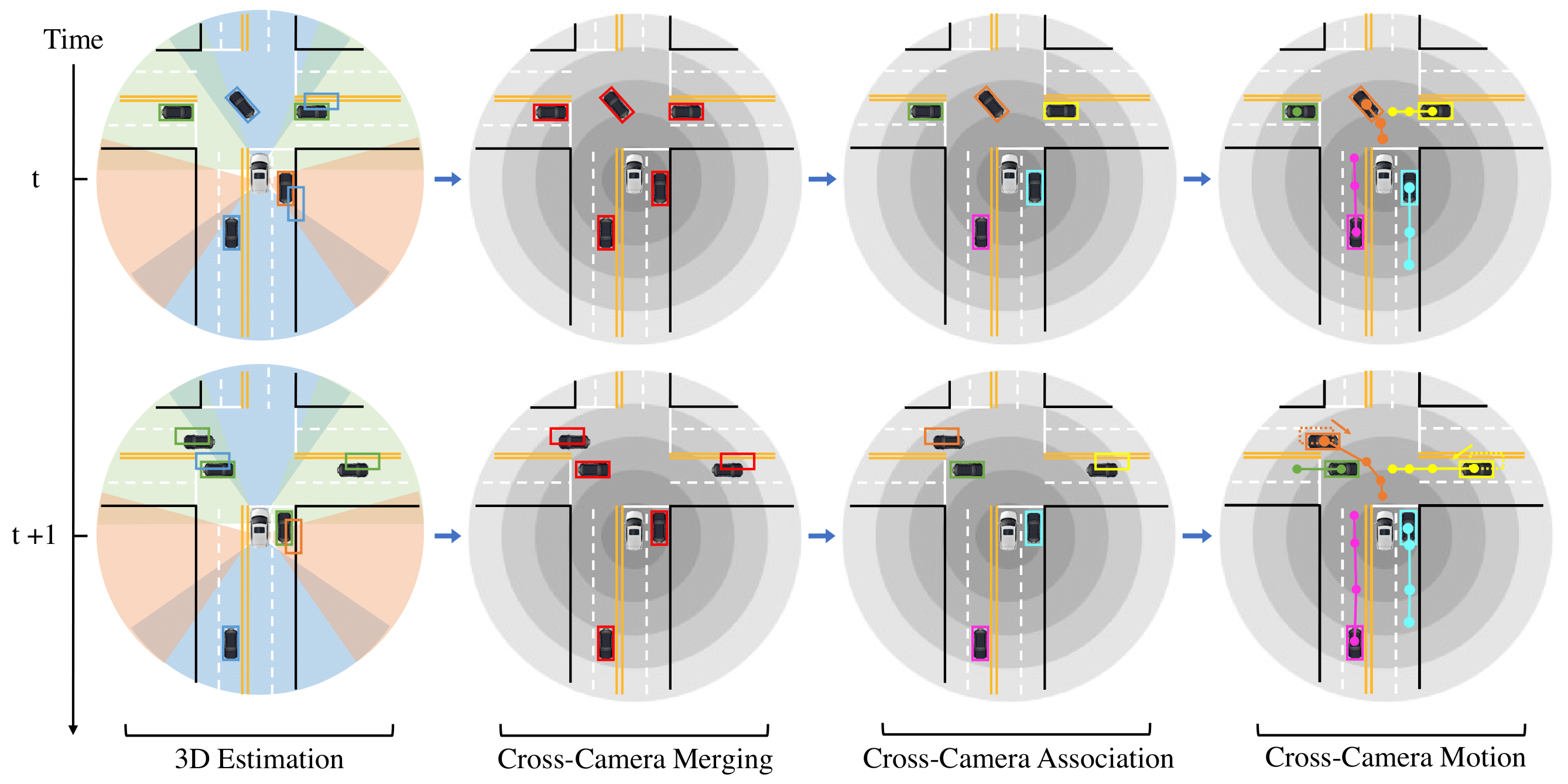
To track the 3D locations and trajectories of the other traffic participants at any given time, modern autonomous vehicles are equipped with multiple cameras that cover the vehicle’s full surroundings. Yet, camera-based 3D object tracking methods prioritize optimizing the single-camera setup and resort to post-hoc fusion in a multi-camera setup. In this paper, we propose a method for panoramic 3D object tracking, called CC-3DT, that associates and models object trajectories both temporally and across views, and improves the overall tracking consistency. In particular, our method fuses 3D detections from multiple cameras before association, reducing identity switches significantly and improving motion modeling. Our experiments on large-scale driving datasets show that fusion before association leads to a large margin of improvement over post-hoc fusion. We set a new state-of-the-art with 12.6% improvement in average multi-object tracking accuracy (AMOTA) among all camera-based methods on the competitive NuScenes 3D tracking benchmark, outperforming previously published methods by 6.5% in AMOTA with the same 3D detector.
Video Overview
Qualitative Results
Paper
 | Tobias Fischer*, Yung-Hsu Yang*, Suryansh Kumar, Min Sun, Fisher Yu CC-3DT: Panoramic 3D Object Tracking via Cross-Camera Fusion CoRL 2022 |
Citation
@inproceedings{cc3dt,
title={CC-3DT: Panoramic 3D Object Tracking via Cross-Camera Fusion},
author={Fischer, Tobias and Yang, Yung-Hsu and Kumar, Suryansh and Sun, Min and Yu, Fisher},
booktitle={6th Annual Conference on Robot Learning},
year={2022}
}