Abstract
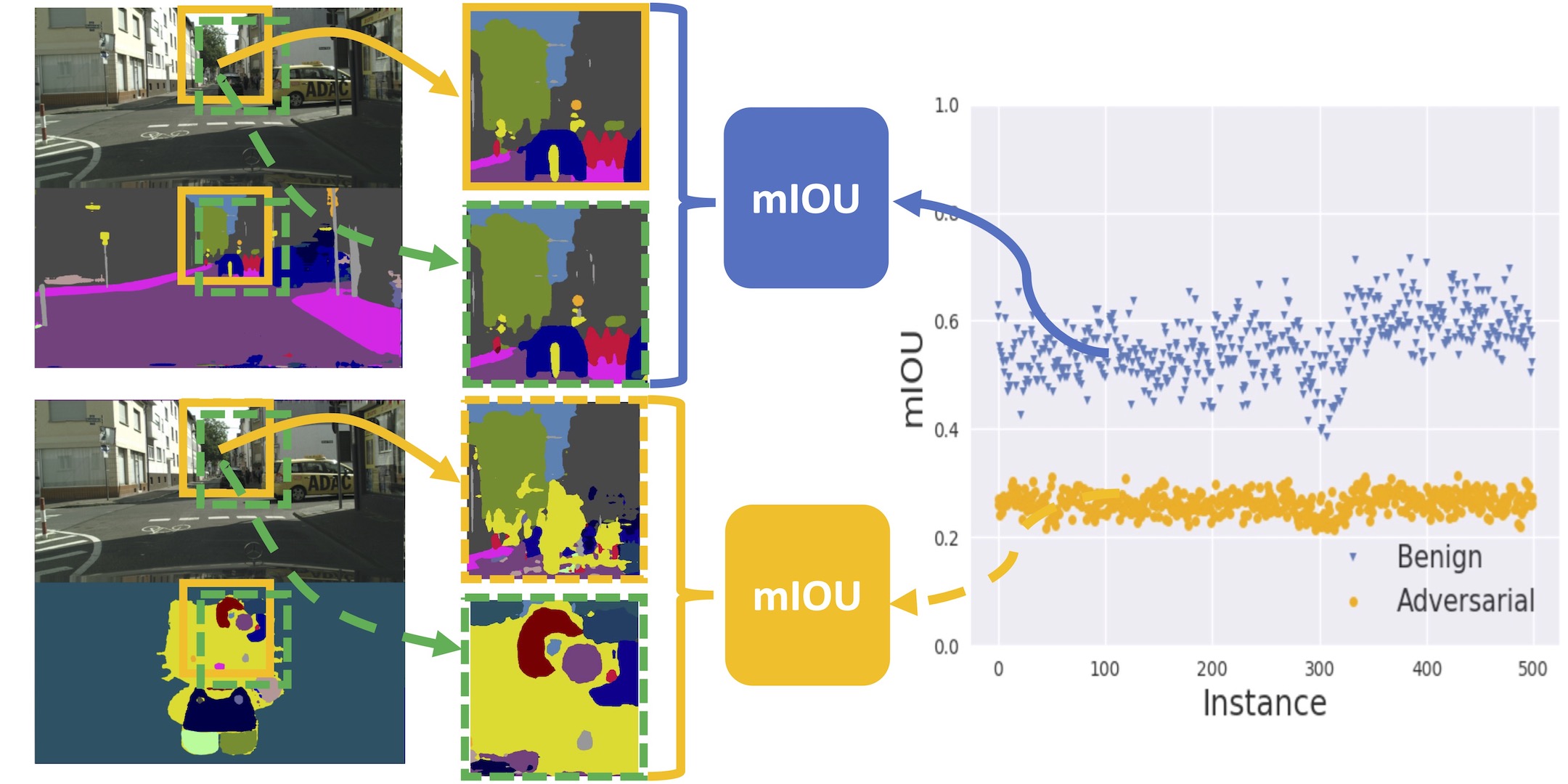
Deep Neural Networks (DNNs) have been widely applied in various recognition tasks. However, recently DNNs have been shown to be vulnerable against adversarial examples, which can mislead DNNs to make arbitrary incorrect predictions. While adversarial examples are well studied in classification tasks, other learning problems may have different properties. For instance, semantic segmentation requires additional components such as dilated convolutions and multiscale processing. In this paper, we aim to characterize adversarial examples based on spatial context information in semantic segmentation. We observe that spatial consistency information can be potentially leveraged to detect adversarial examples robustly even when a strong adaptive attacker has access to the model and detection strategies. We also show that adversarial examples based on attacks considered within the paper barely transfer among models, even though transferability is common in classification. Our observations shed new light on developing adversarial attacks and defenses to better understand the vulnerabilities of DNNs.
Paper
 | Chaowei Xiao, Ruizhi Deng, Bo Li, Fisher Yu, Mingyan Liu, Dawn Song Characterizing Adversarial Examples Based on Spatial Consistency Information for Semantic Segmentation ECCV 2018 |
Citation
@inproceedings{xiao2018characterizing,
title={Characterizing adversarial examples based on spatial consistency information for semantic segmentation},
author={Xiao, Chaowei and Deng, Ruizhi and Li, Bo and Yu, Fisher and Liu, Mingyan and Song, Dawn},
booktitle={Proceedings of the European Conference on Computer Vision (ECCV)},
pages={217--234},
year={2018}
}