Abstract
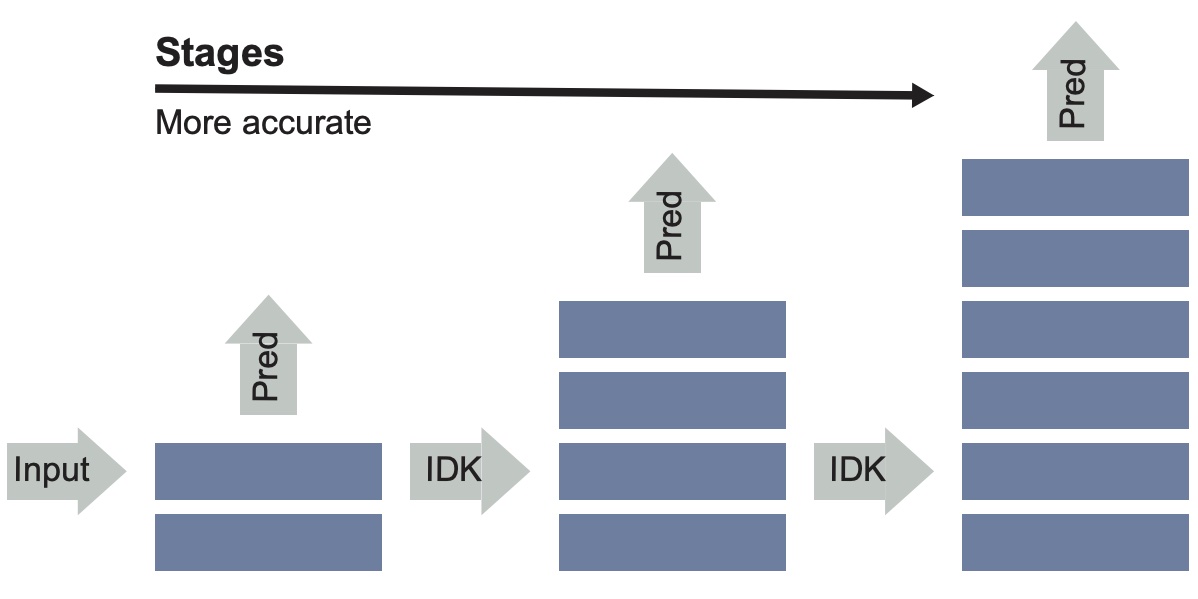
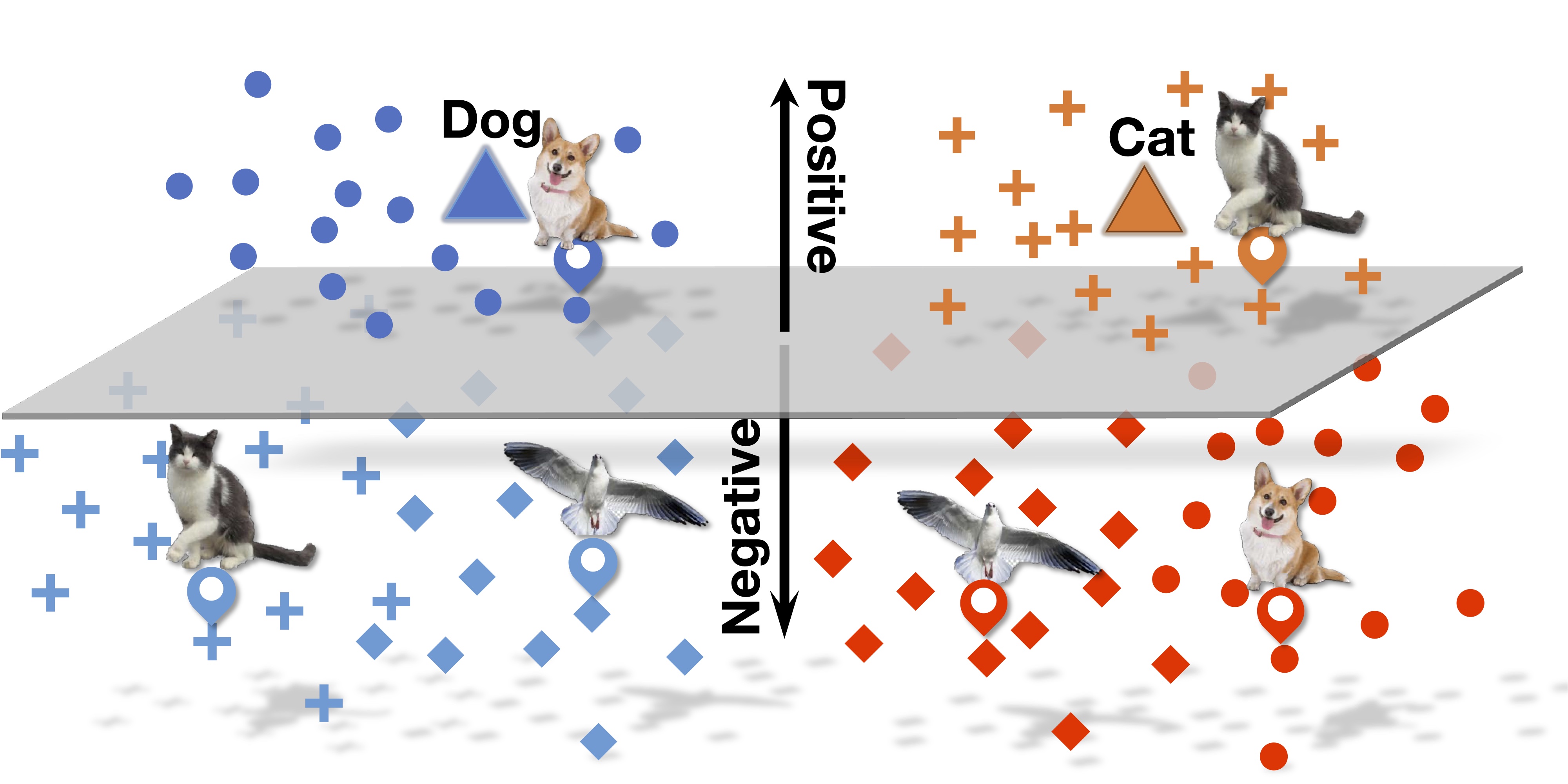
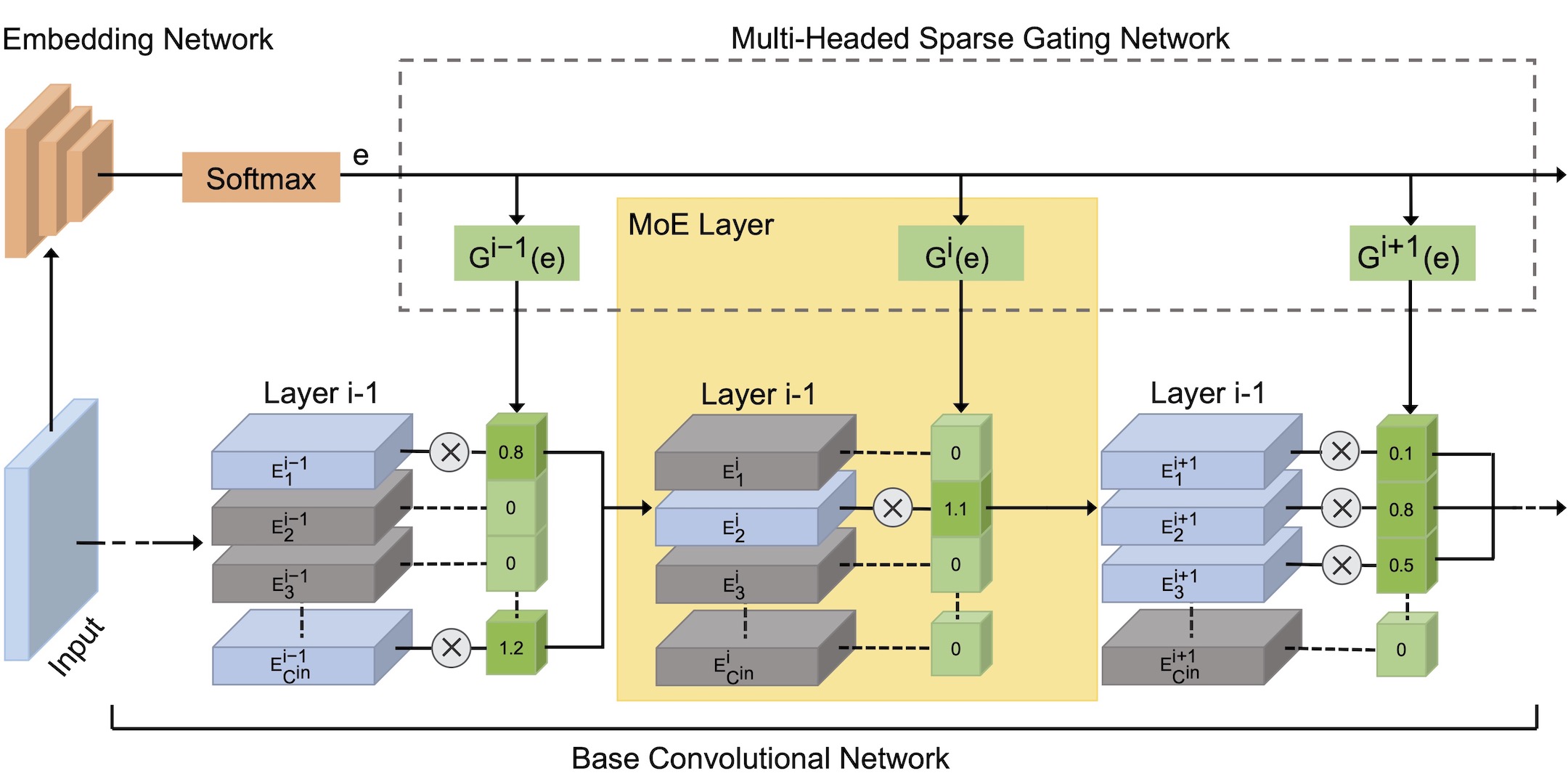
Larger networks generally have greater representational power at the cost of increased computational complexity. Sparsifying such networks has been an active area of research but has been generally limited to static regularization or dynamic approaches using reinforcement learning. We explore a mixture of experts (MoE) approach to deep dynamic routing, which activates certain experts in the network on a per-example basis. Our novel DeepMoE architecture increases the representational power of standard convolutional networks by adaptively sparsifying and recalibrating channel-wise features in each convolutional layer. We employ a multi-headed sparse gating network to determine the selection and scaling of channels for each input, leveraging exponential combinations of experts within a single convolutional network. Our proposed architecture is evaluated on four benchmark datasets and tasks, and we show that Deep-MoEs are able to achieve higher accuracy with lower computation than standard convolutional networks.
Paper
 | Xin Wang, Fisher Yu, Lisa Dunlap, Yi-An Ma, Ruth Wang, Azalia Mirhoseini, Trevor Darrell, Joseph E. Gonzalez Deep Mixture of Experts via Shallow Embedding UAI 2019 |
Citation
@inproceedings{wang2020deep,
title={Deep mixture of experts via shallow embedding},
author={Wang, Xin and Yu, Fisher and Dunlap, Lisa and Ma, Yi-An and Wang, Ruth and Mirhoseini, Azalia and Darrell, Trevor and Gonzalez, Joseph E},
booktitle={Uncertainty in Artificial Intelligence},
year={2019},
}