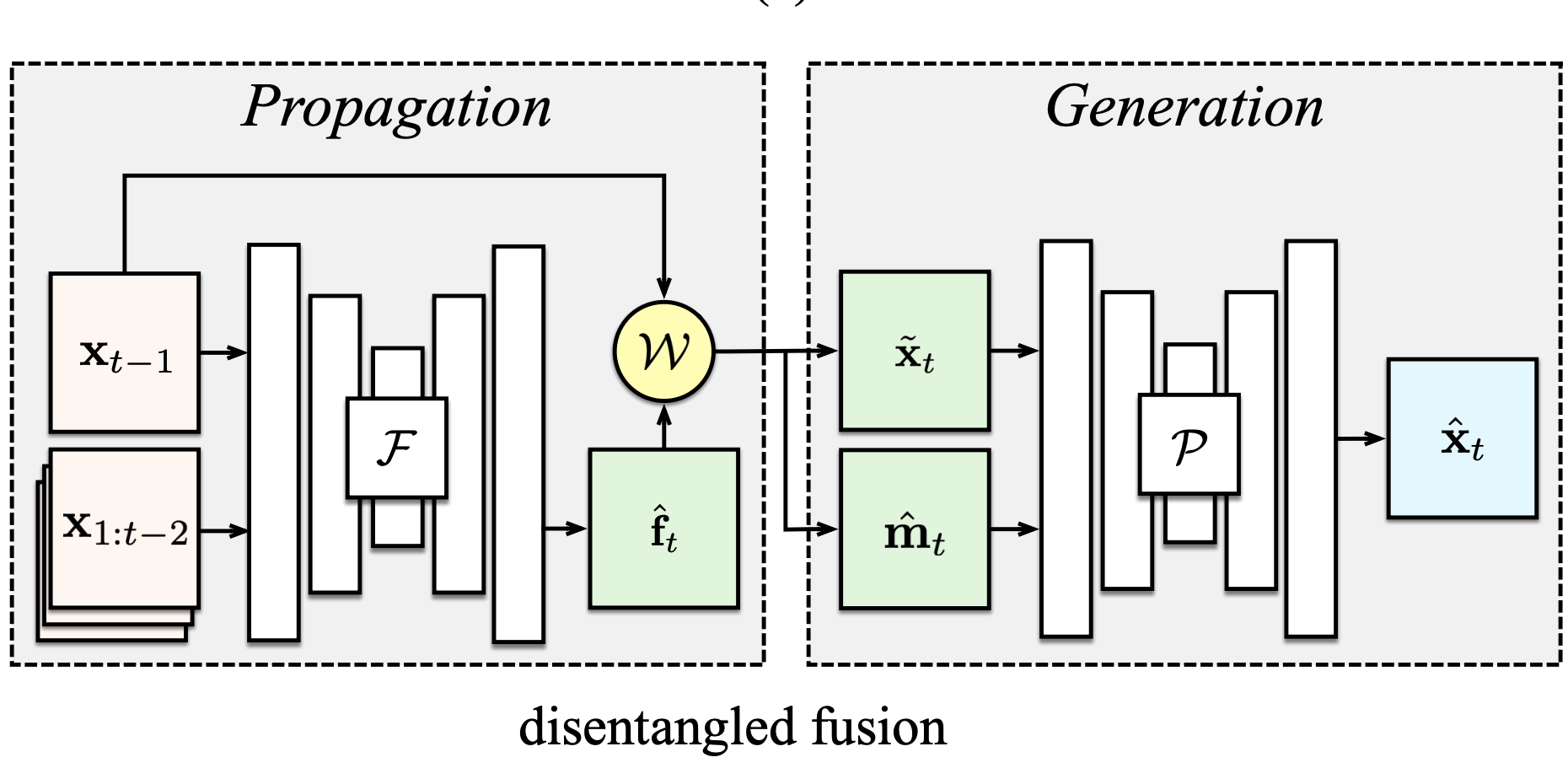
Abstract
A dynamic scene has two types of elements: those that move fluidly and can be predicted from previous frames, and those which are disoccluded (exposed) and cannot be extrapolated. Prior approaches to video prediction typically learn either to warp or to hallucinate future pixels, but not both. In this paper, we describe a computational model for high-fidelity video prediction which disentangles motion-specific propagation from motion-agnostic generation. We introduce a confidence-aware warping operator which gates the output of pixel predictions from a flow predictor for non-occluded regions and from a context encoder for occluded regions. Moreover, in contrast to prior works where confidence is jointly learned with flow and appearance using a single network, we compute confidence after a warping step, and employ a separate network to inpaint exposed regions. Empirical results on both synthetic and real datasets show that our disentangling approach provides better occlusion maps and produces both sharper and more realistic predictions compared to strong baselines.
Paper
 | Hang Gao, Huazhe Xu, Qi-Zhi Cai, Ruth Wang, Fisher Yu, Trevor Darrell Disentangling Propagation and Generation for Video Prediction ICCV 2019 |
Citation
@inproceedings{gao2019disentangling,
title={Disentangling propagation and generation for video prediction},
author={Gao, Hang and Xu, Huazhe and Cai, Qi-Zhi and Wang, Ruth and Yu, Fisher and Darrell, Trevor},
booktitle={Proceedings of the IEEE/CVF International Conference on Computer Vision},
pages={9006--9015},
year={2019}
}
