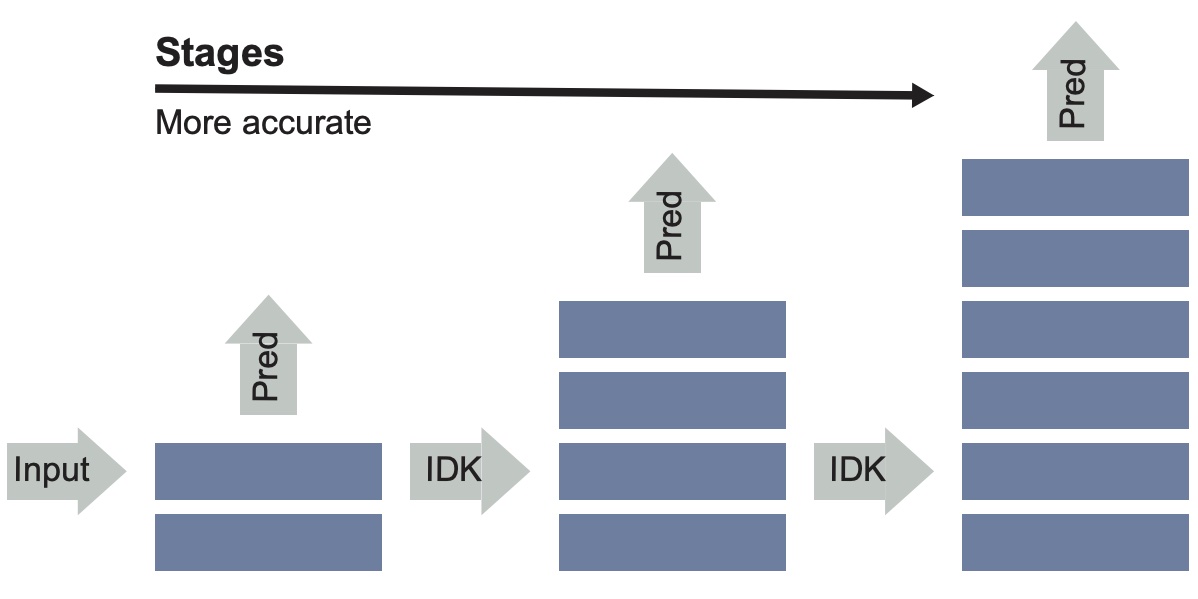
Abstract
Advances in deep learning have led to substantial increases in prediction accuracy but have been accompanied by increases in the cost of rendering predictions. We conjecture that for a majority of real-world inputs, the recent advances in deep learning have created models that effectively “over-think” on simple inputs. In this paper we revisit the classic question of building model cascades that primarily leverage class asymmetry to reduce cost. We introduce the “I Don’t Know” (IDK) prediction cascades framework, a general framework to systematically compose a set of pre-trained models to accelerate inference without a loss in prediction accuracy. We propose two search based methods for constructing cascades as well as a new cost-aware objective within this framework. The proposed IDK cascade framework can be easily adopted in the existing model serving systems without additional model retraining. We evaluate the proposed techniques on a range of benchmarks to demonstrate the effectiveness of the proposed framework.
Paper
 | Xin Wang, Yujia Luo, Daniel Crankshaw, Alexey Tumanov, Fisher Yu, Joseph E. Gonzalez IDK Cascades: Fast Deep Learning by Learning not to Overthink UAI 2018 |
Citation
@inproceedings{wang2017idk,
title="IDK Cascades: Fast Deep Learning by Learning not to Overthink.",
author="Xin {Wang} and Yujia {Luo} and Daniel {Crankshaw} and Alexey {Tumanov} and Fisher {Yu} and Joseph E. {Gonzalez",
booktitle="UAI",
pages="580--590",
year="2017"
}