Publications
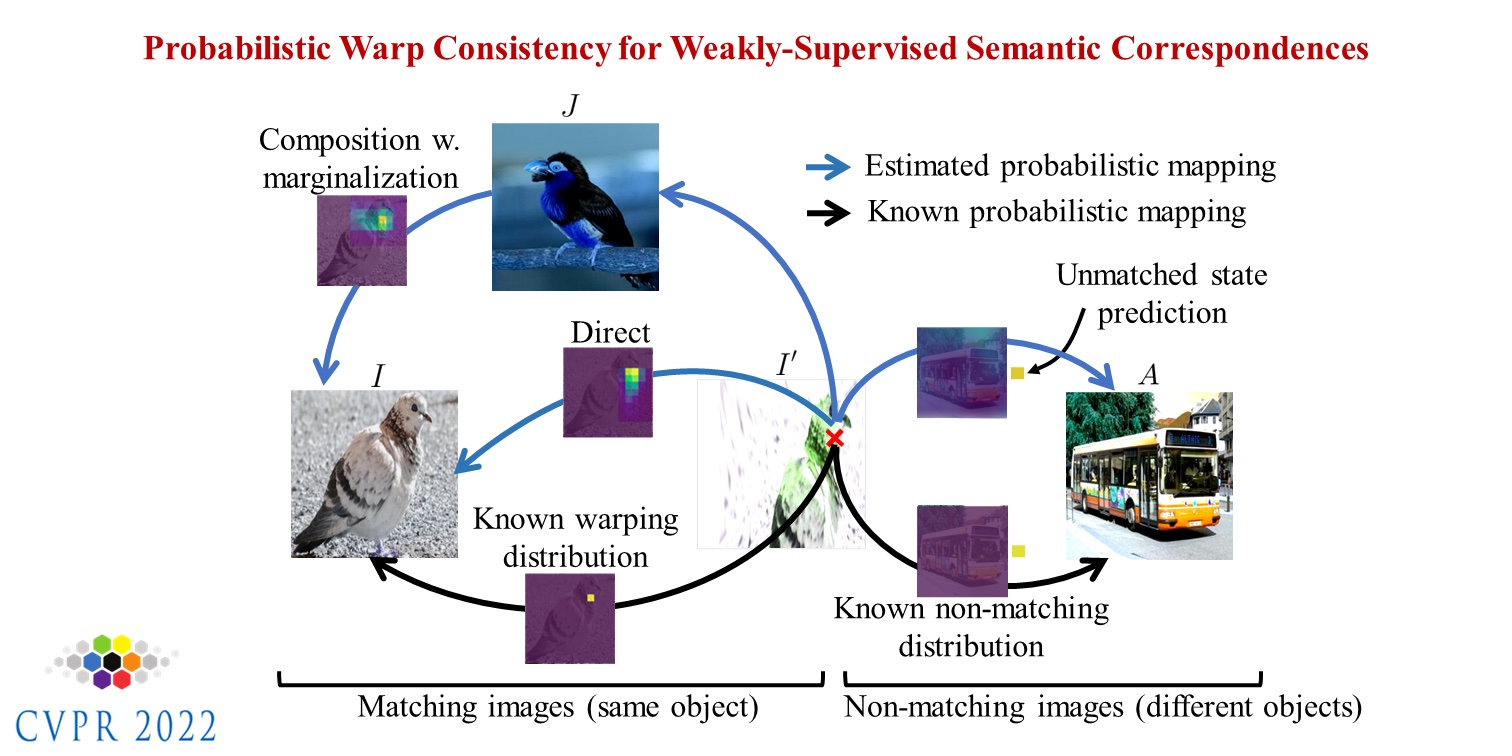
Probabilistic Warp Consistency for Weakly-Supervised Semantic Correspondences
CVPR 2022 We propose Probabilistic Warp Consistency, a weakly-supervised learning objective for semantic matching.
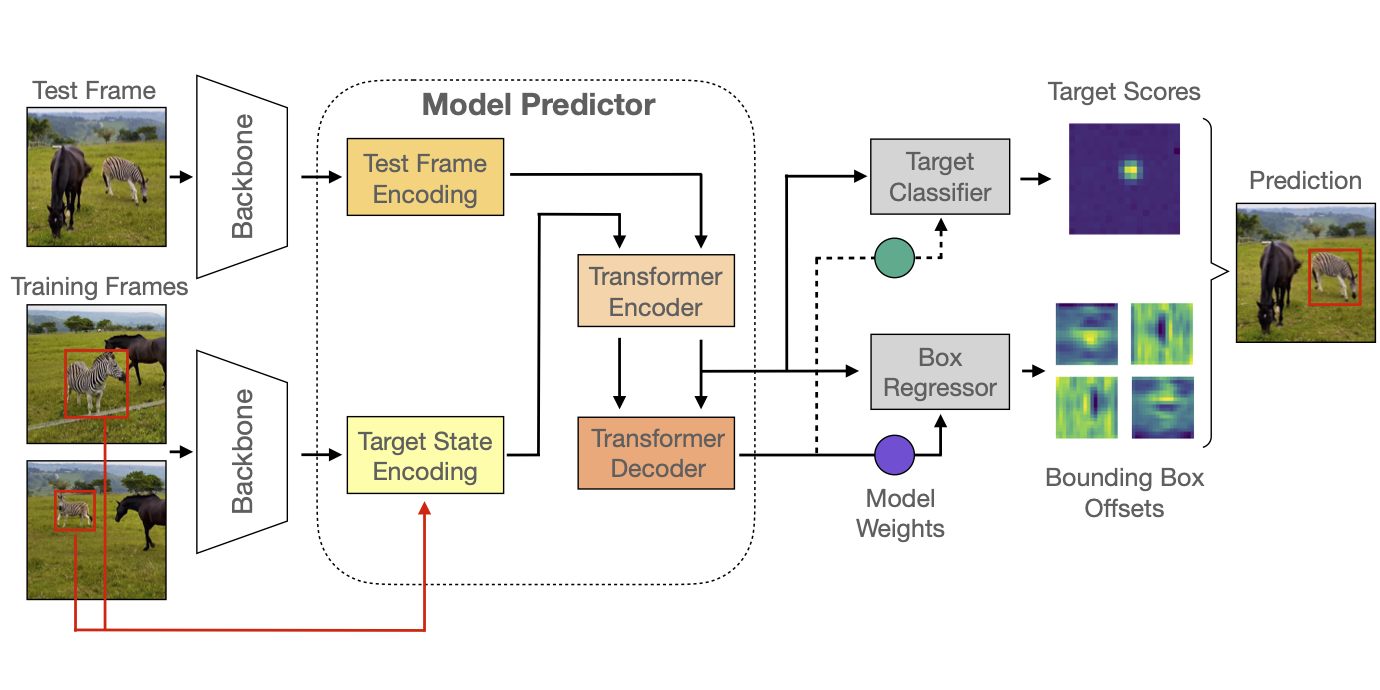
Transforming Model Prediction for Tracking
CVPR 2022 We propose a tracker architecture employing a Transformer-based model prediction module.
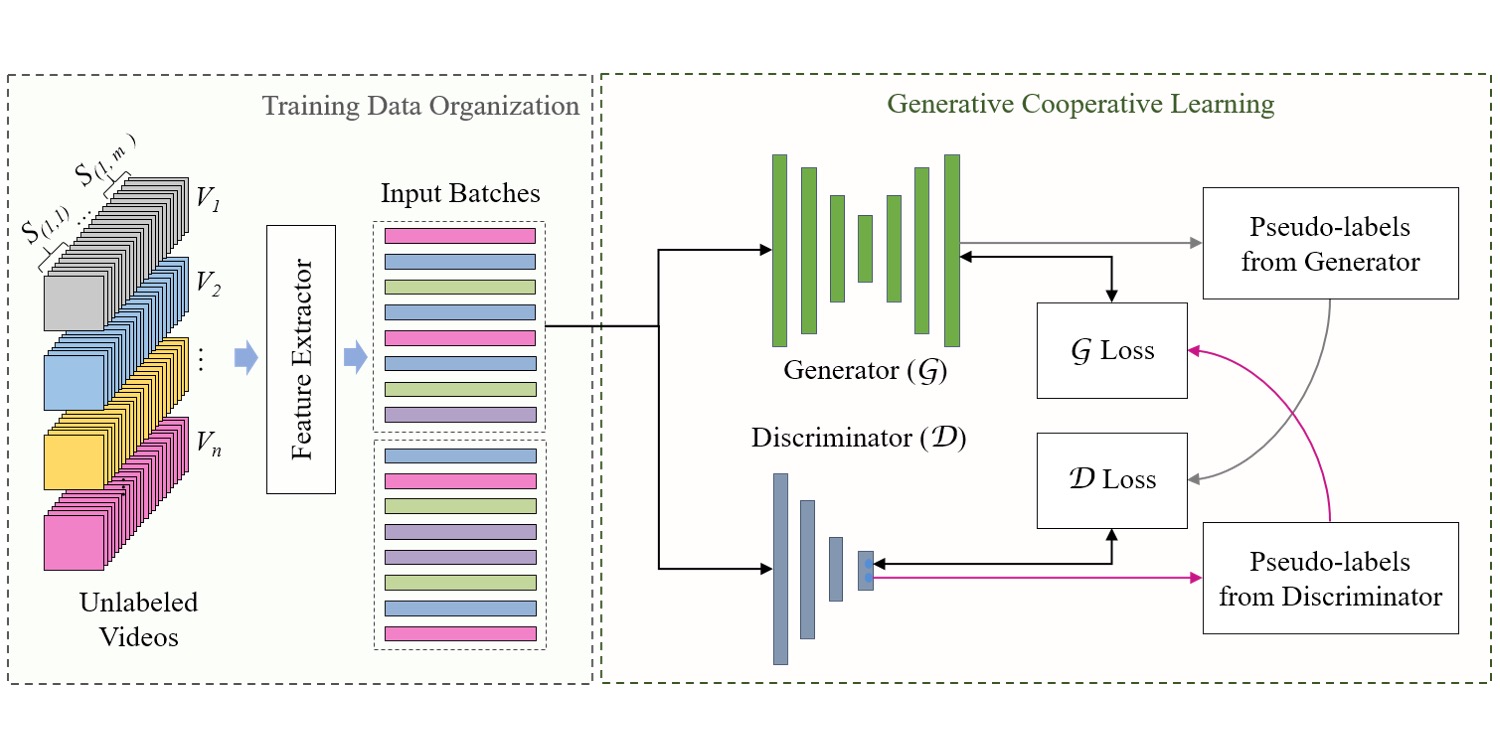
Generative Cooperative Learning for Unsupervised Video Anomaly Detection
CVPR 2022 Our method exploits the low frequency of anomalies towards building a cross-supervision between a generator and a discriminator.

RePaint: Inpainting using Denoising Diffusion Probabilistic Models
CVPR 2022 We propose a Denoising Diffusion Probabilistic Model (DDPM) based inpainting approach that is applicable to even extreme masks.

LiDAR Snowfall Simulation for Robust 3D Object Detection
CVPR 2022 Oral We propose a physically based method to simulate the effect of snowfall on real clear weather LiDAR point clouds.
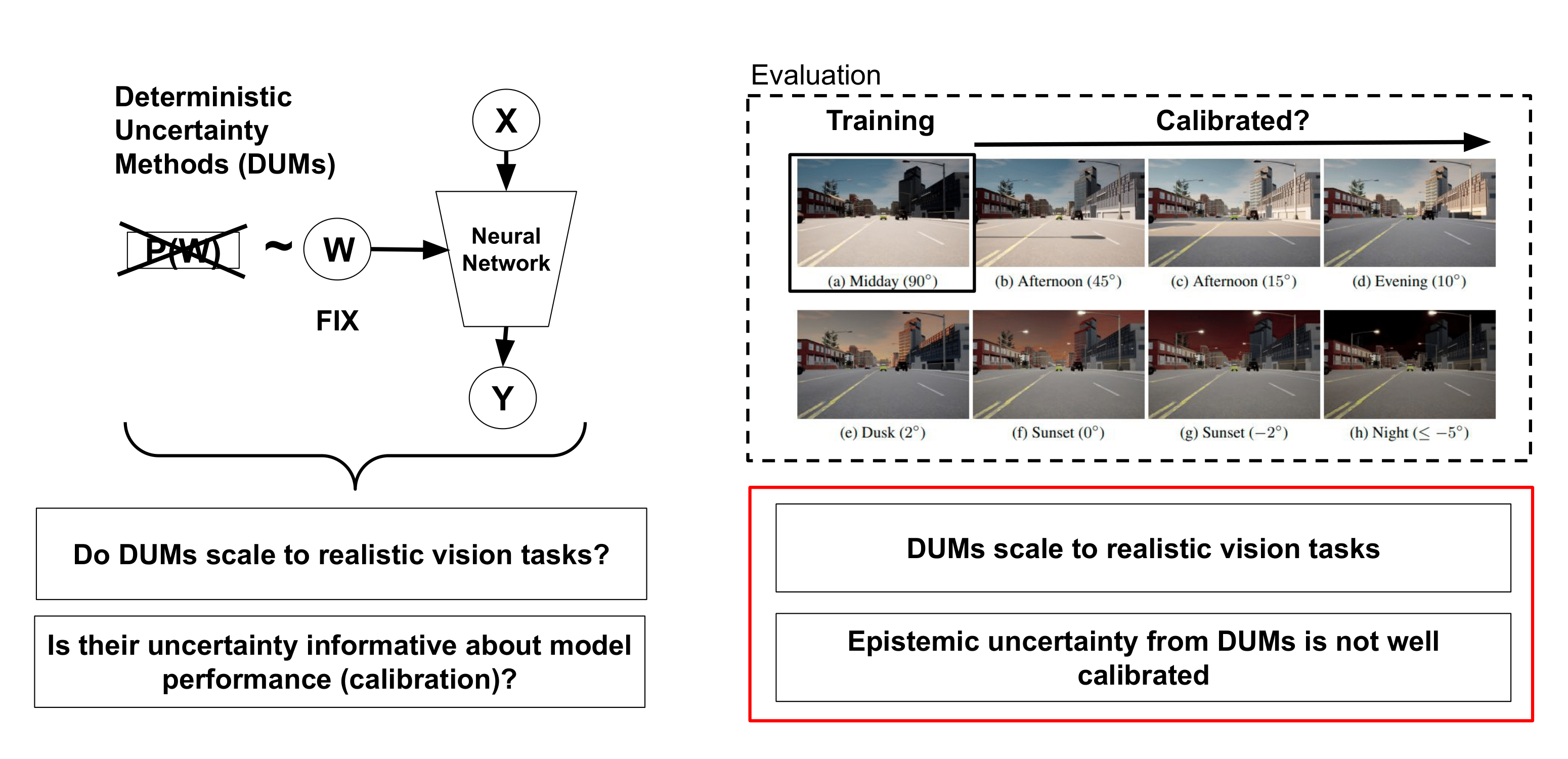
On the Practicality of Deterministic Epistemic Uncertainty
ICML 2022 We provide a taxonomy of DUMs, evaluate their calibration under continuous distributional shifts, and extend them to semantic segmentation.
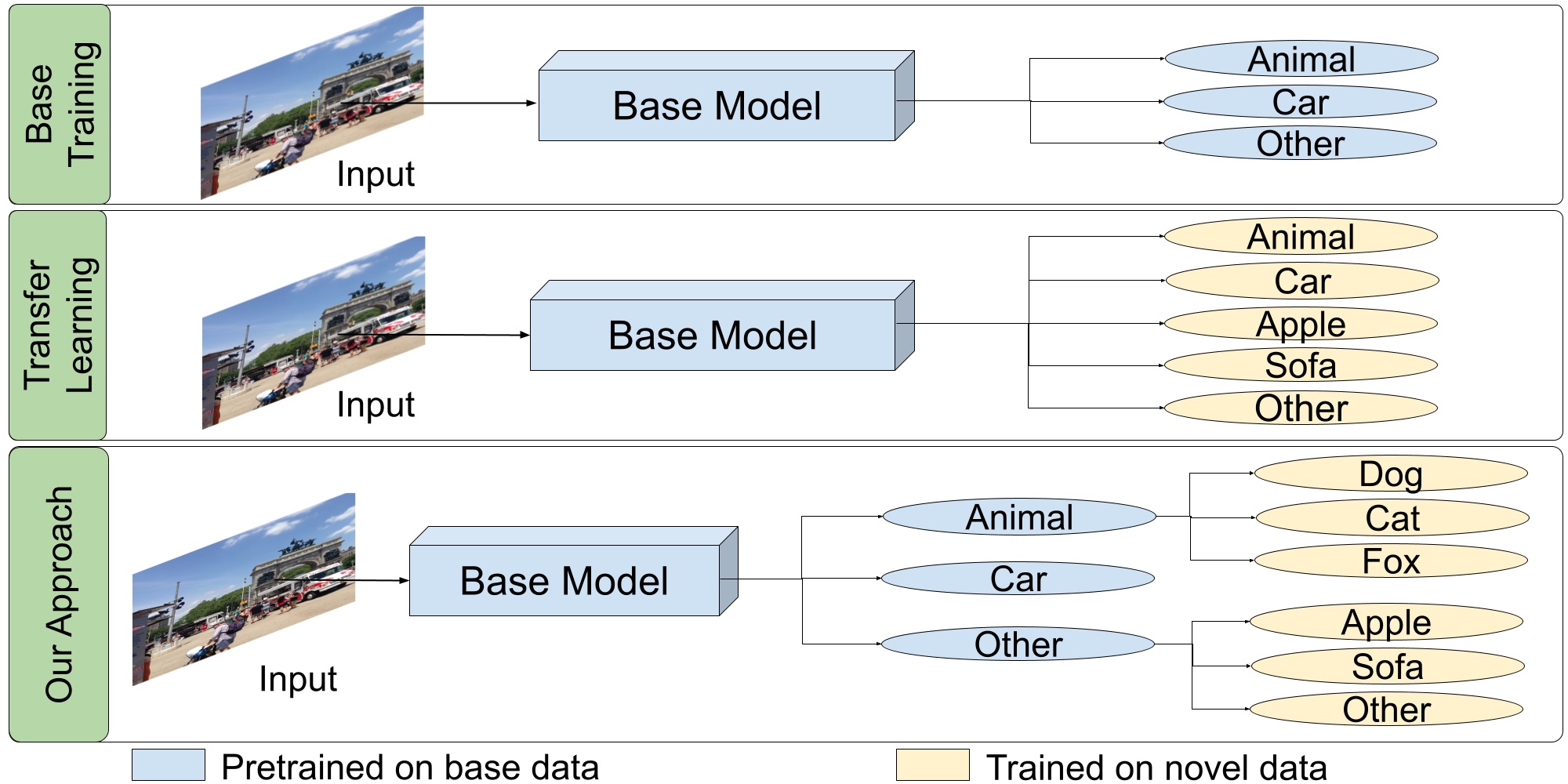
Fast Hierarchical Learning for Few-Shot Object Detection
IROS 2022 We pose few-shot detection as a hierarchical learning problem, where the novel classes are treated as the child classes of existing base classes and the background class.
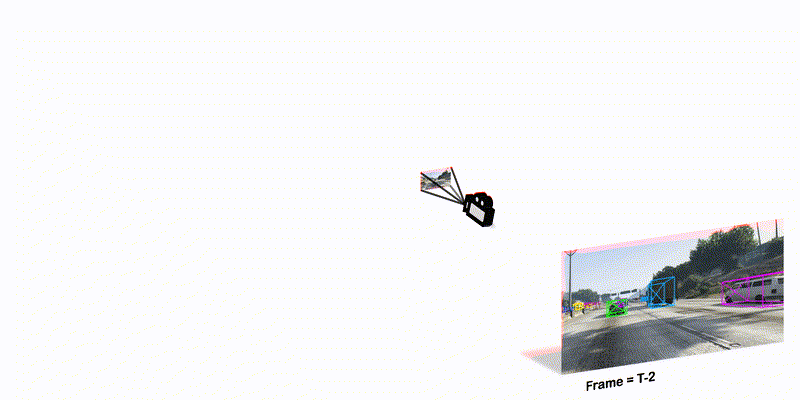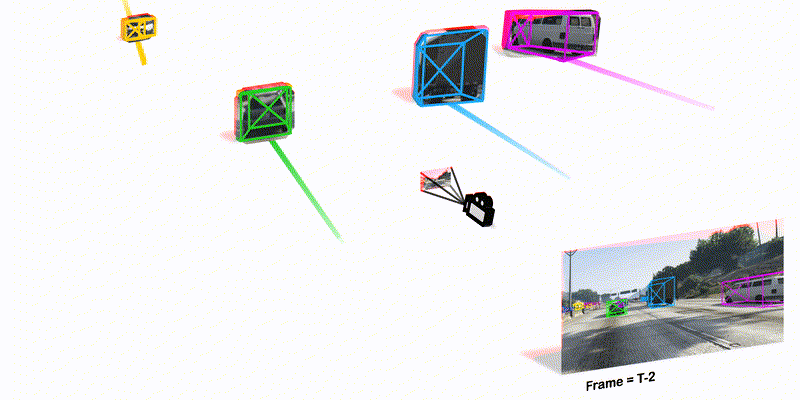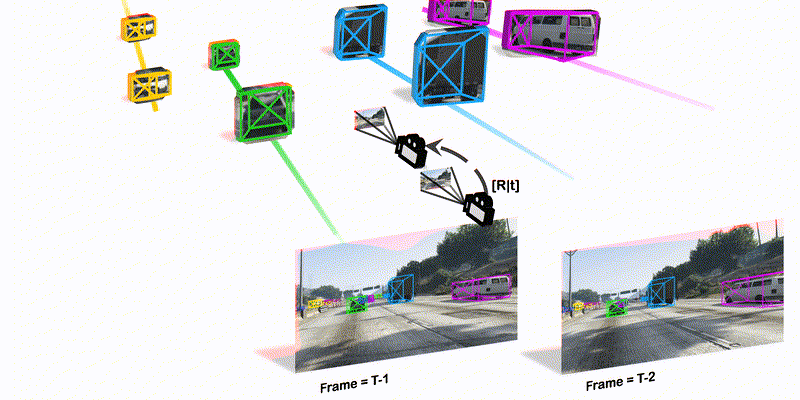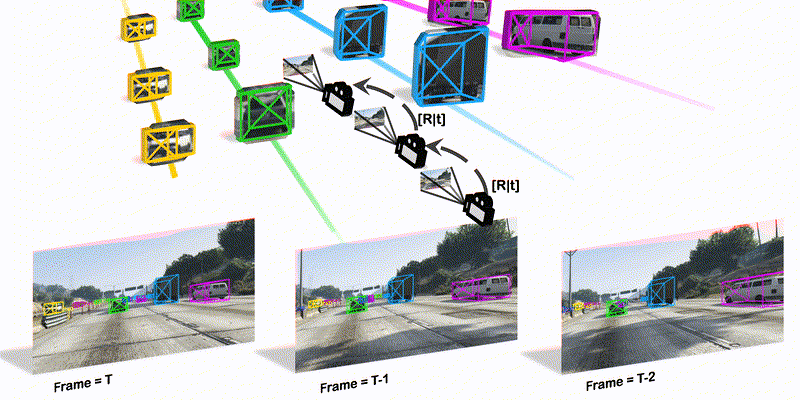
Monocular Quasi-Dense 3D Object Tracking
TPAMI 2022 We combine quasi-dense tracking on 2D images and motion prediction in 3D space to achieve significant advance in 3D object tracking from monocular videos.

Normalizing Flow as a Flexible Fidelity Objective for Photo-Realistic Super-resolution
WACV 2022 We explore general flows as a fidelity-based alternative to the L1 objective.
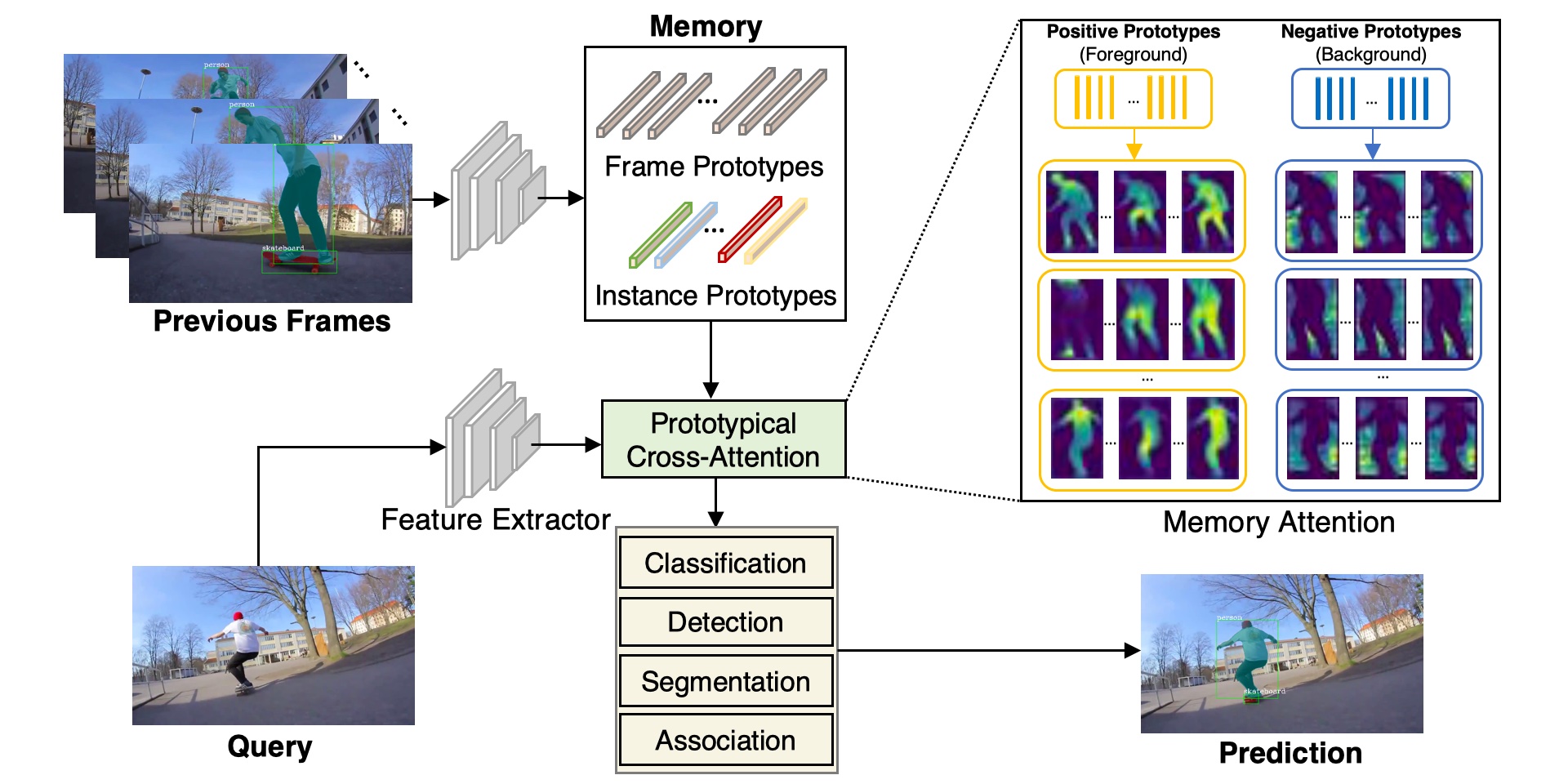
Prototypical Cross-Attention Networks for Multiple Object Tracking and Segmentation
NeurIPS 2021 Spotlight We propose Prototypical Cross-Attention Network (PCAN), capable of leveraging rich spatio-temporal information for online multiple object tracking and segmentation.
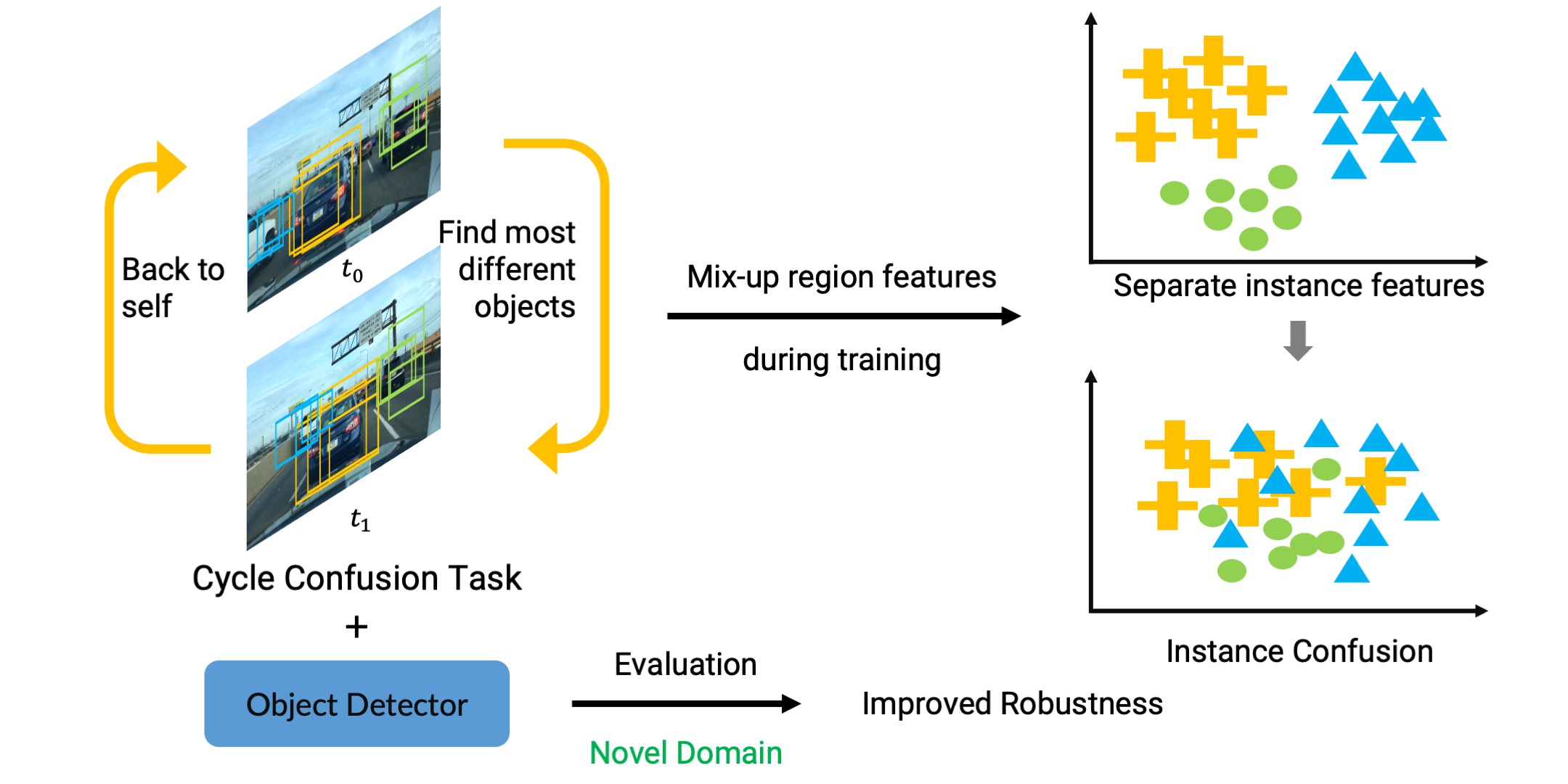
Robust Object Detection via Instance-Level Temporal Cycle Confusion
ICCV 2021 We study the effectiveness of auxiliary self-supervised tasks to improve the out-of-distribution generalization of object detectors.

Warp Consistency for Unsupervised Learning of Dense Correspondences
ICCV 2021 Oral We propose Warp Consistency, an unsupervised learning objective for dense correspondence regression.
Exploring Cross-Image Pixel Contrast for Semantic Segmentation
ICCV 2021 Oral We propose a pixel-wise contrastive algorithm for semantic segmentation in the fully supervised setting.

Deep Reparametrization of Multi-Frame Super-Resolution and Denoising
ICCV 2021 Oral We propose a deep reparametrization of the maximum a posteriori formulation commonly employed in multi-frame image restoration tasks.
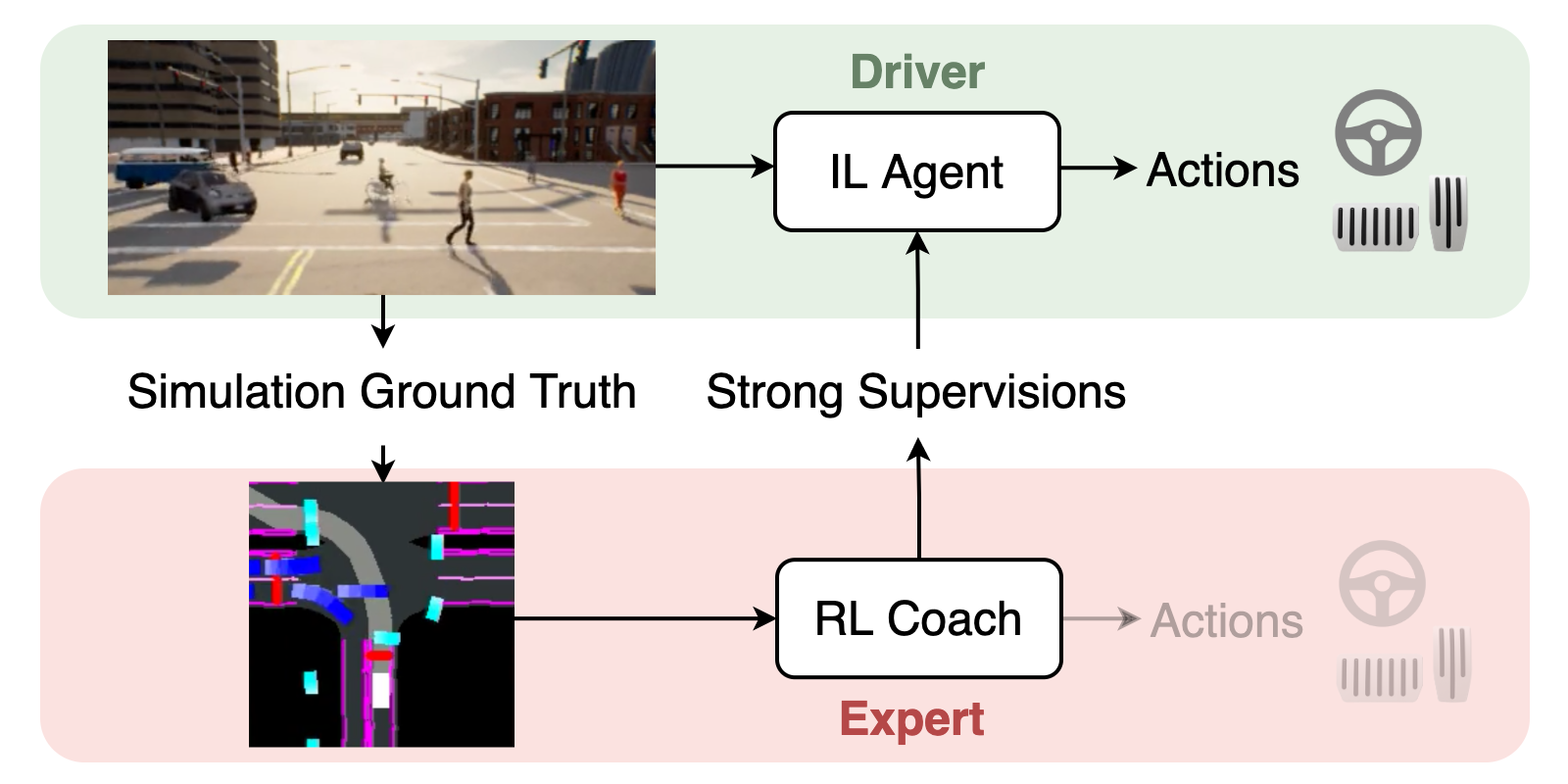
End-to-End Urban Driving by Imitating a Reinforcement Learning Coach
ICCV 2021 We demonstrated that an RL coach (Roach) would be a better choice to supervise imitation learning agents.
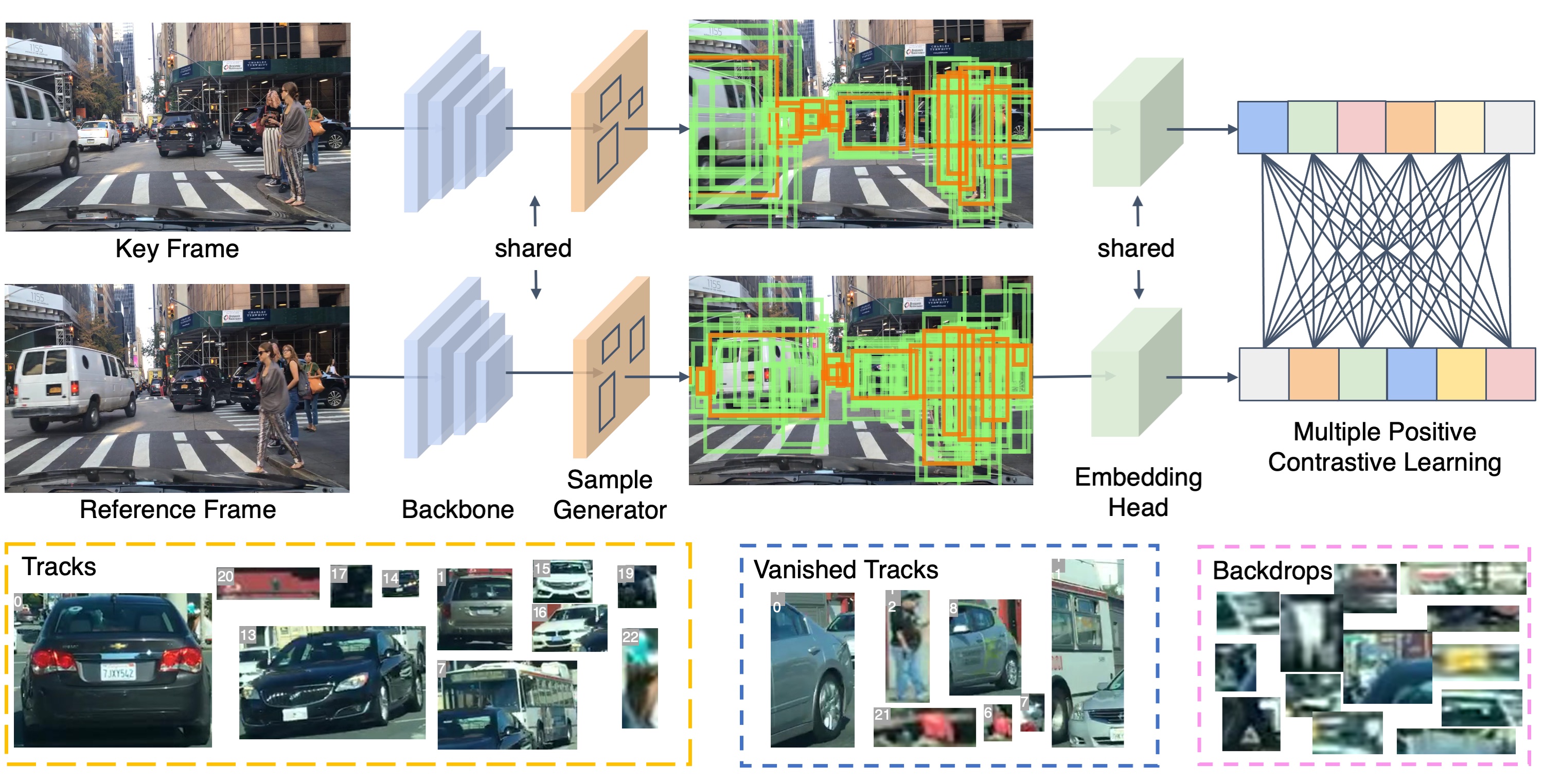
Quasi-Dense Similarity Learning for Multiple Object Tracking
CVPR 2021 Oral We propose a simple yet effective multi-object tracking method in this paper.

Instance-Aware Predictive Navigation in Multi-Agent Environments
ICRA 2021 A new visual model-based RL method with consideration of multiple hypotheses for future object movement.

BDD100K: A Diverse Driving Dataset for Heterogeneous Multitask Learning
CVPR 2020 Oral The largest driving video dataset for heterogeneous multitask learning.
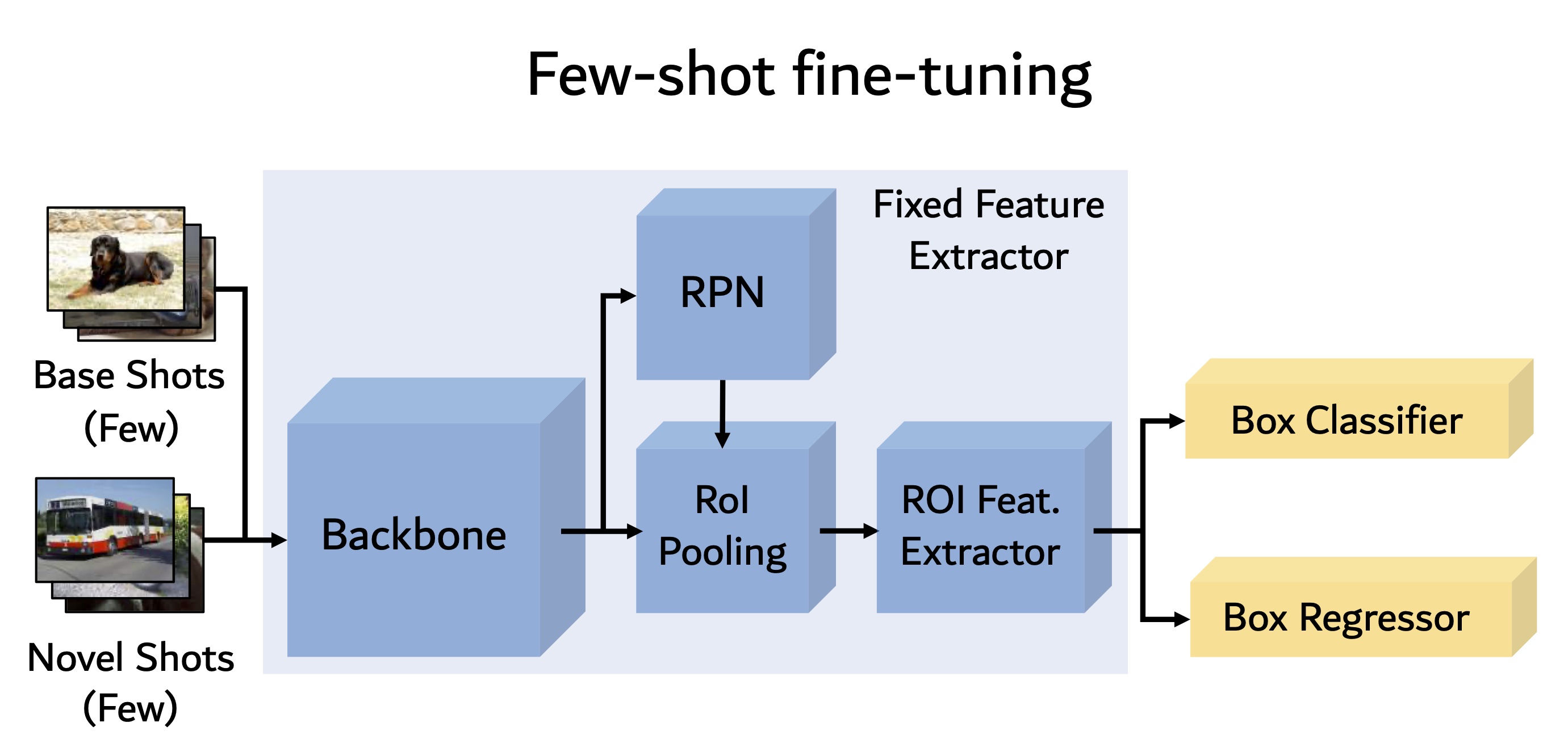
Frustratingly Simple Few-Shot Object Detection
ICML 2020 State-of-the-art few-shot detection method with backpropagation learning.
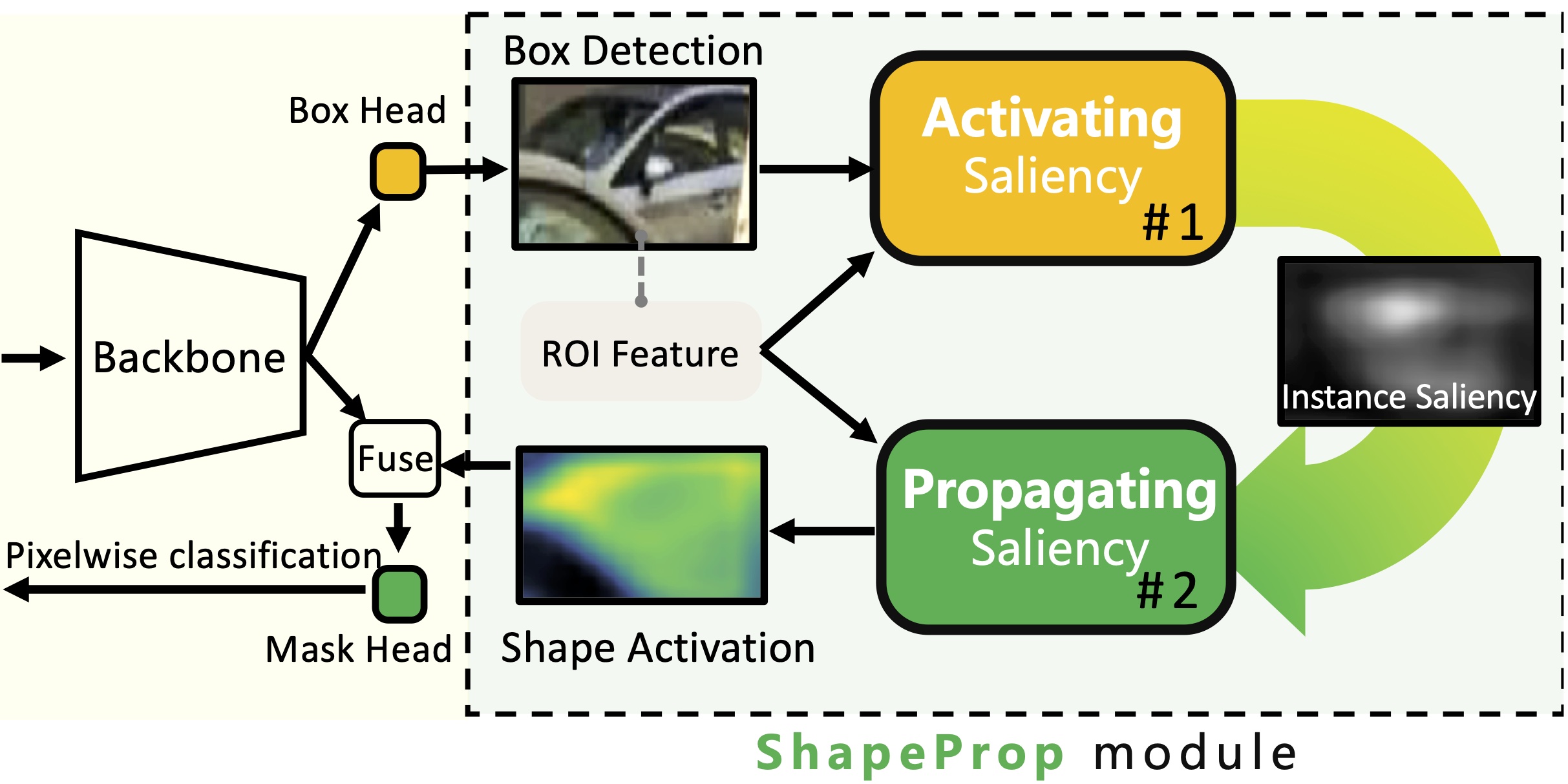
Learning Saliency Propagation for Semi-Supervised Instance Segmentation
CVPR 2020 We propose a ShapeProp module to propagate information between object detection and segmentation supervisions for Semi-Supervised Instance Segmentation.
Joint Monocular 3D Vehicle Detection and Tracking
ICCV 2019 We propose a novel online framework for 3D vehicle detection and tracking from monocular videos.
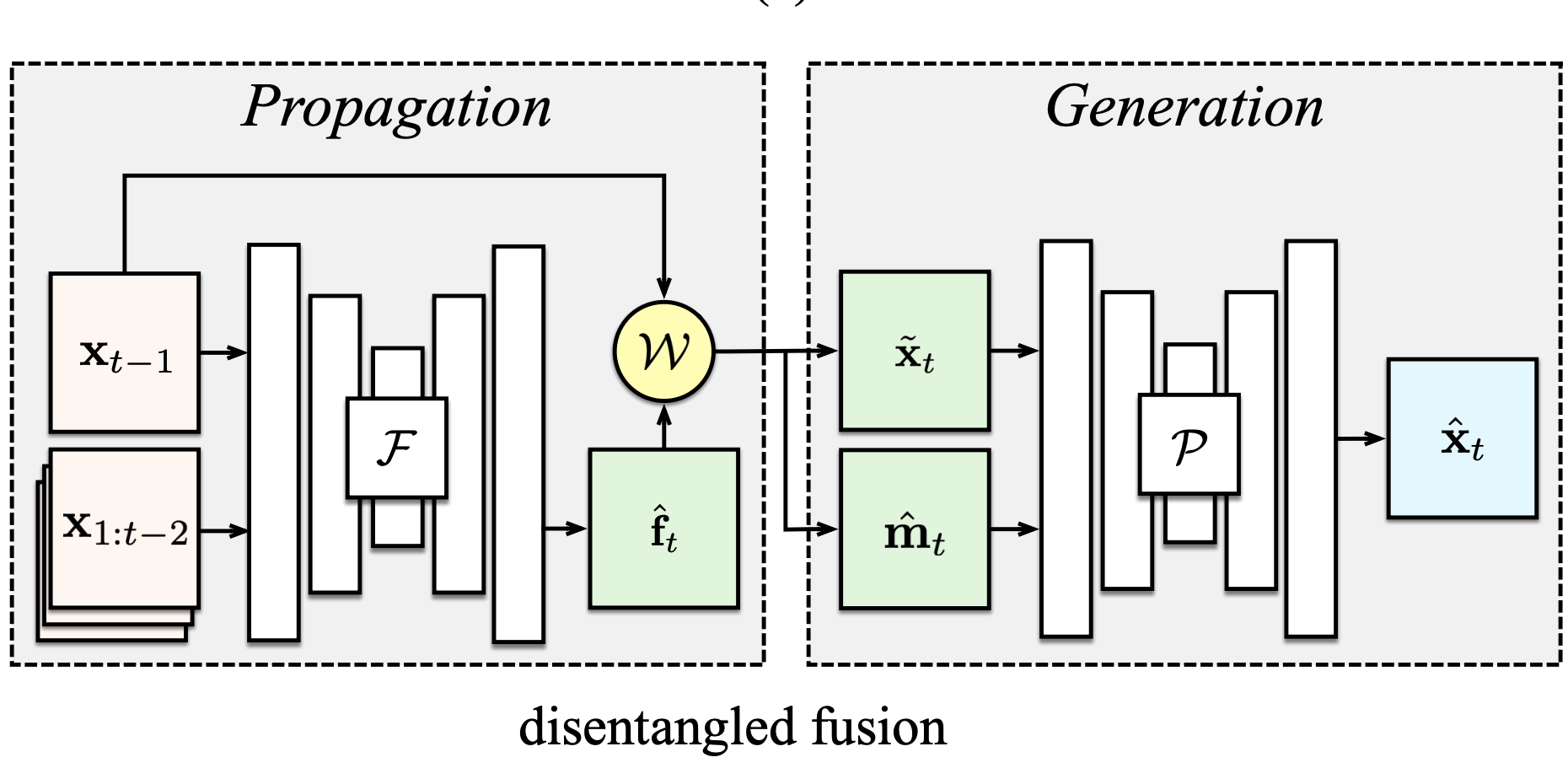
Disentangling Propagation and Generation for Video Prediction
ICCV 2019 We describe a computational model for high-fidelity video prediction which disentangles motion-specific propagation from motion-agnostic generation.

Few Shot Object Detection via Feature Reweighting
ICCV 2019 We develop a few-shot object detector that can learn to detect novel objects from only a few annotated examples.
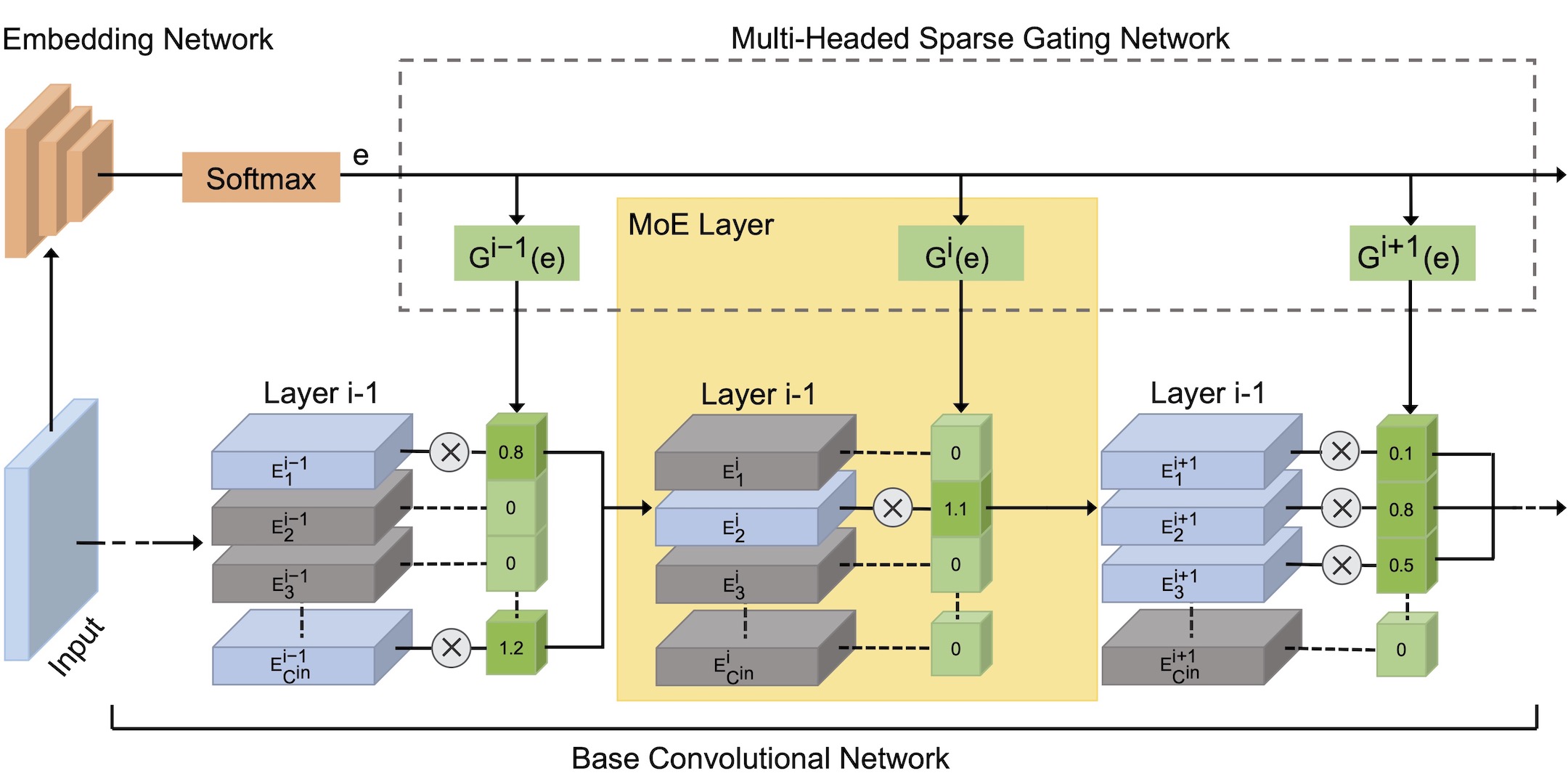
Deep Mixture of Experts via Shallow Embedding
UAI 2019 We explore a mixture of experts (MoE) approach to deep dynamic routing, which activates certain experts in the network on a per-example basis.