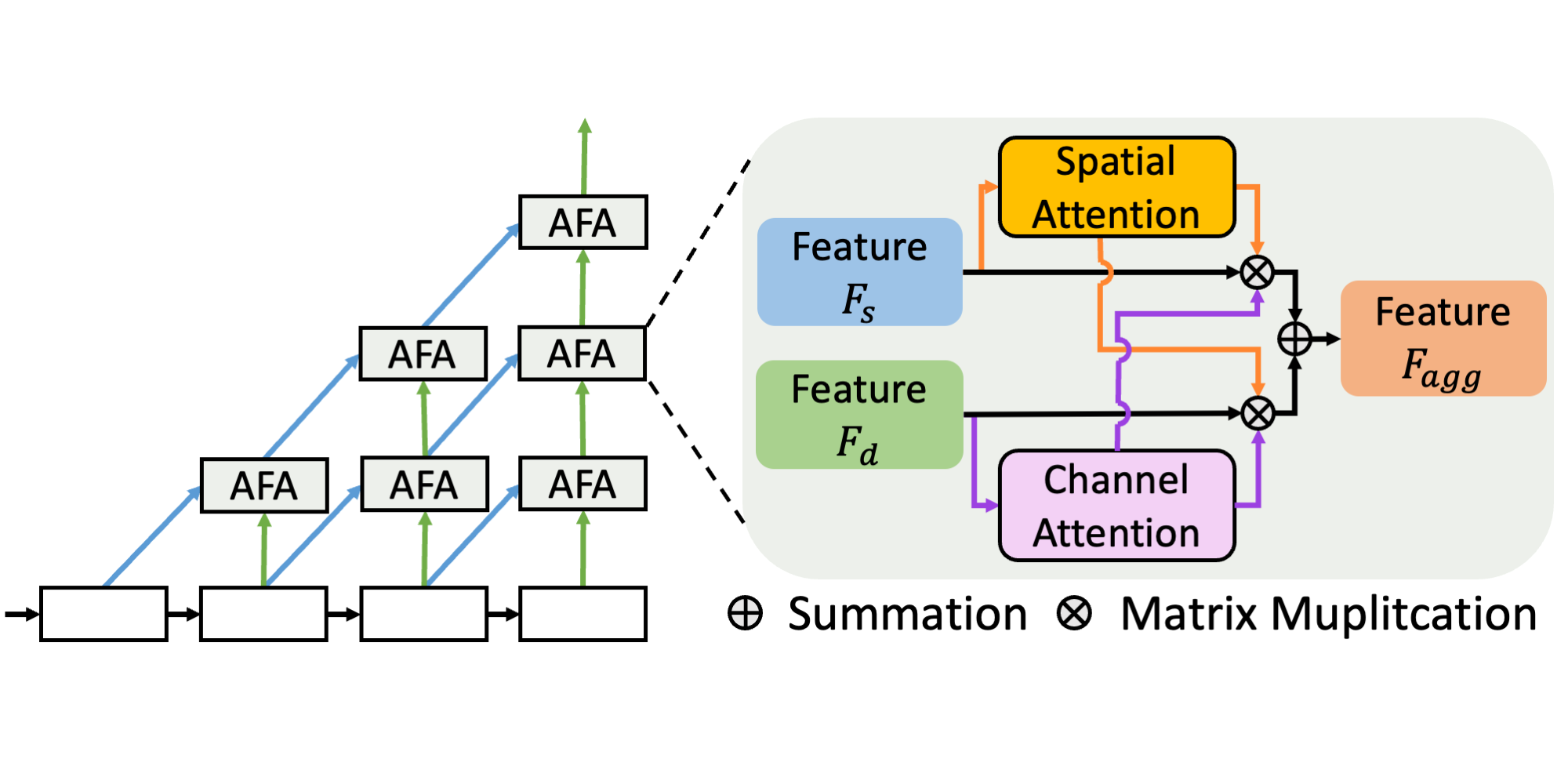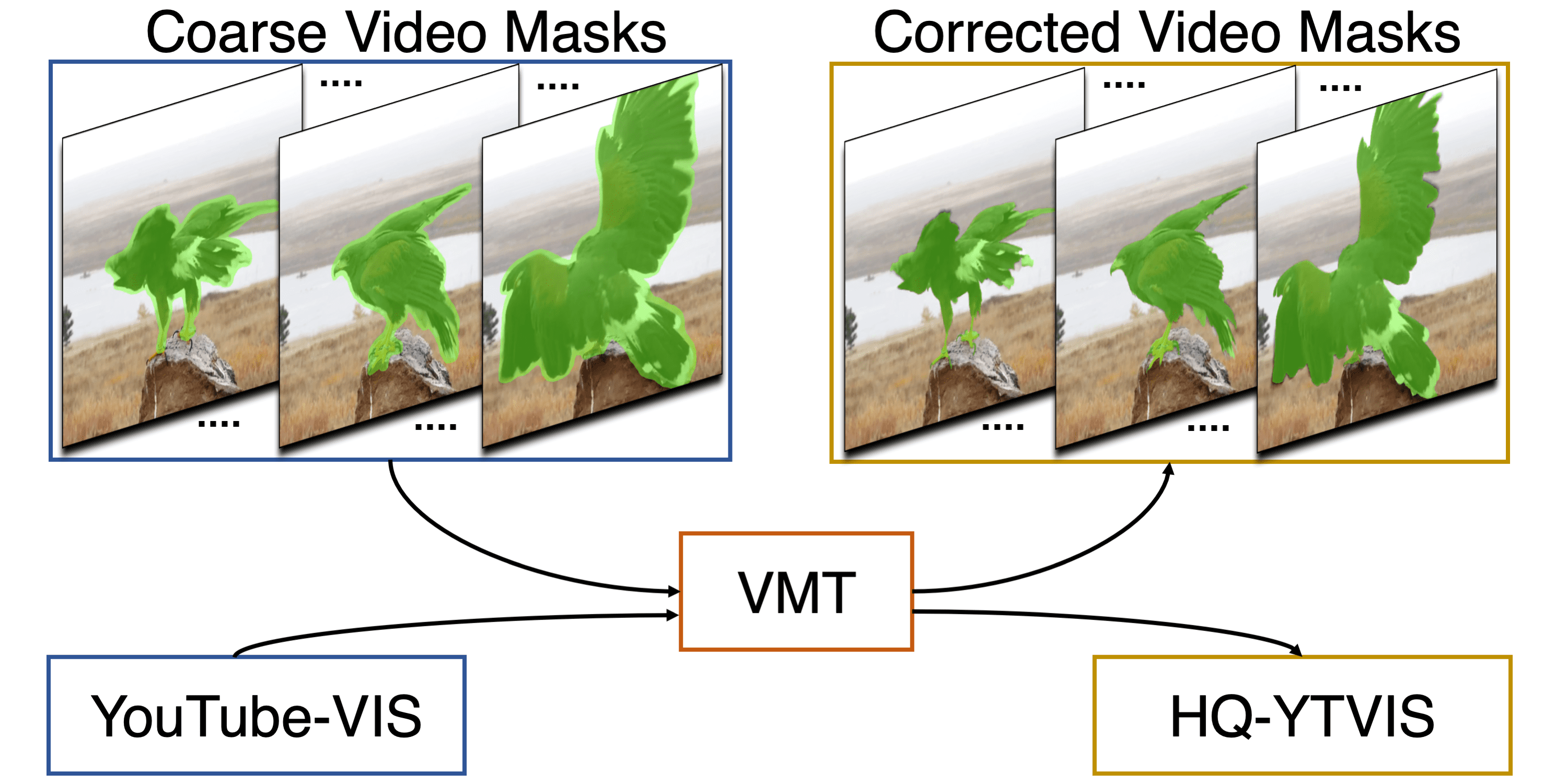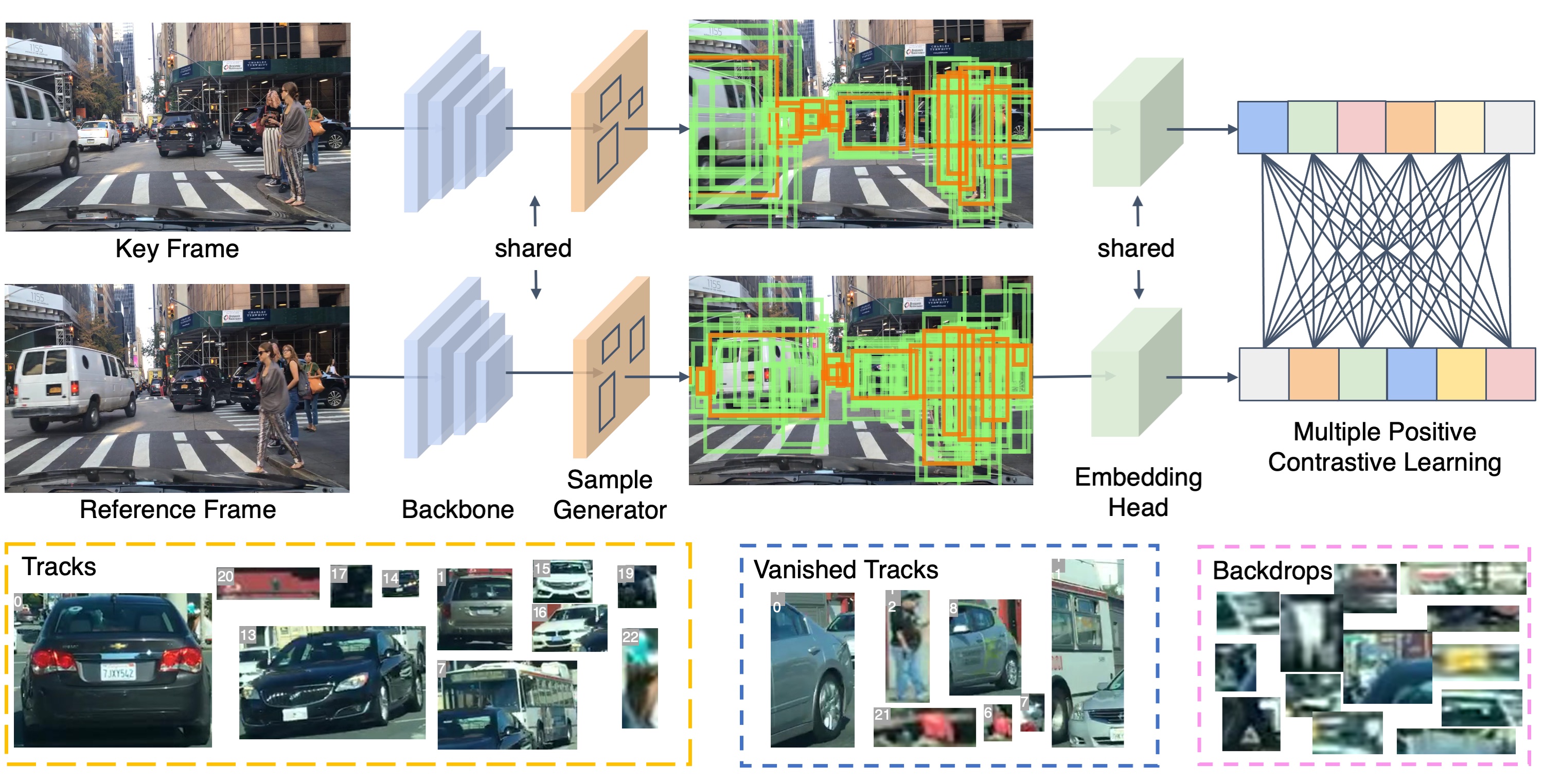
Abstract
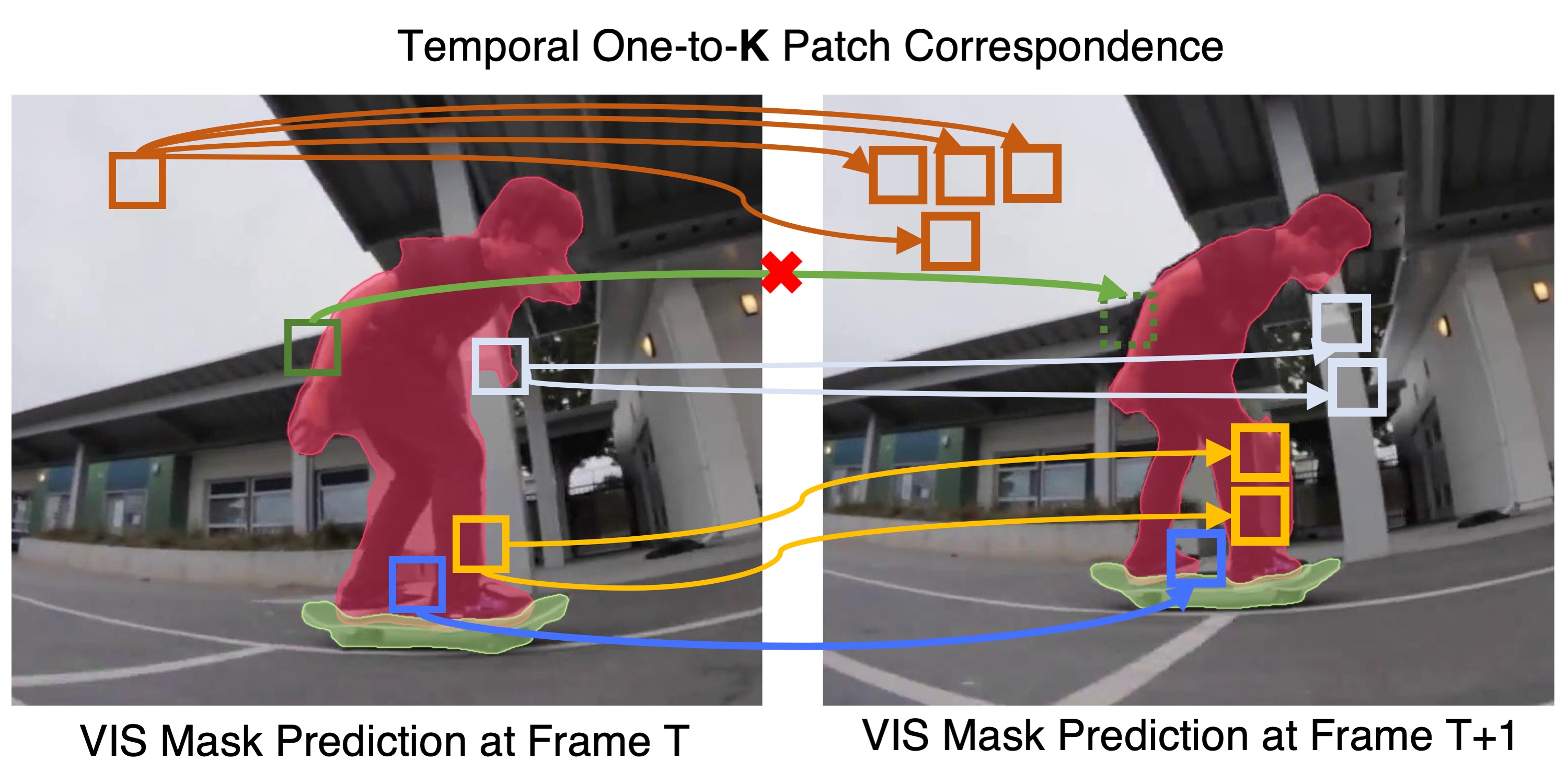
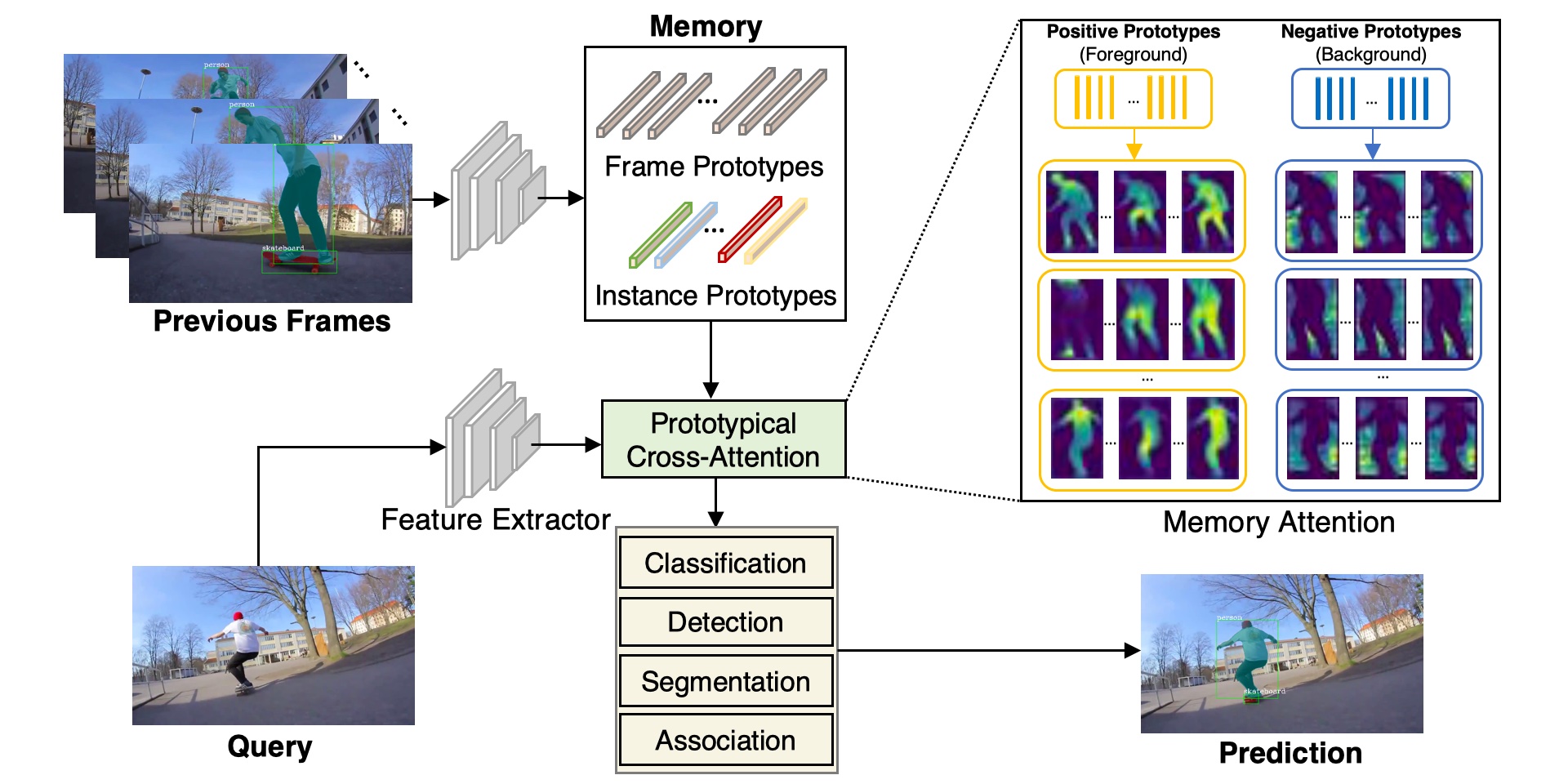
Multiple object tracking and segmentation requires detecting, tracking, and segmenting objects belonging to a set of given classes. Most approaches only exploit the temporal dimension to address the association problem, while relying on single frame predictions for the segmentation mask itself. We propose Prototypical Cross-Attention Network (PCAN), capable of leveraging rich spatio-temporal information for online multiple object tracking and segmentation. PCAN first distills a space-time memory into a set of prototypes and then employs cross-attention to retrieve rich information from the past frames. To segment each object, PCAN adopts a prototypical appearance module to learn a set of contrastive foreground and background prototypes, which are then propagated over time. Extensive experiments demonstrate that PCAN outperforms current video instance tracking and segmentation competition winners on both Youtube-VIS and BDD100K datasets, and shows efficacy to both one-stage and two-stage segmentation frameworks.
Video
Poster

BDD100K Prediction Examples
There are the examples of running PCAN on BDD100K based on QDTrack for bounding box tracking.
Quantitative Results

Paper
 | Lei Ke, Xia Li, Martin Danelljan, Yu-Wing Tai, Chi-Keung Tang, Fisher Yu Prototypical Cross-Attention Networks for Multiple Object Tracking and Segmentation NeurIPS 2021 Spotlight |
Code

github.com/SysCV/pcan
Citation
@inproceedings{pcan,
author = {Ke, Lei and Li, Xia and Danelljan, Martin and Tai, Yu-Wing and Tang, Chi-Keung and Yu, Fisher},
booktitle = {Advances in Neural Information Processing Systems},
title = {Prototypical Cross-Attention Networks for Multiple Object Tracking and Segmentation},
year = {2021}
}