Abstract
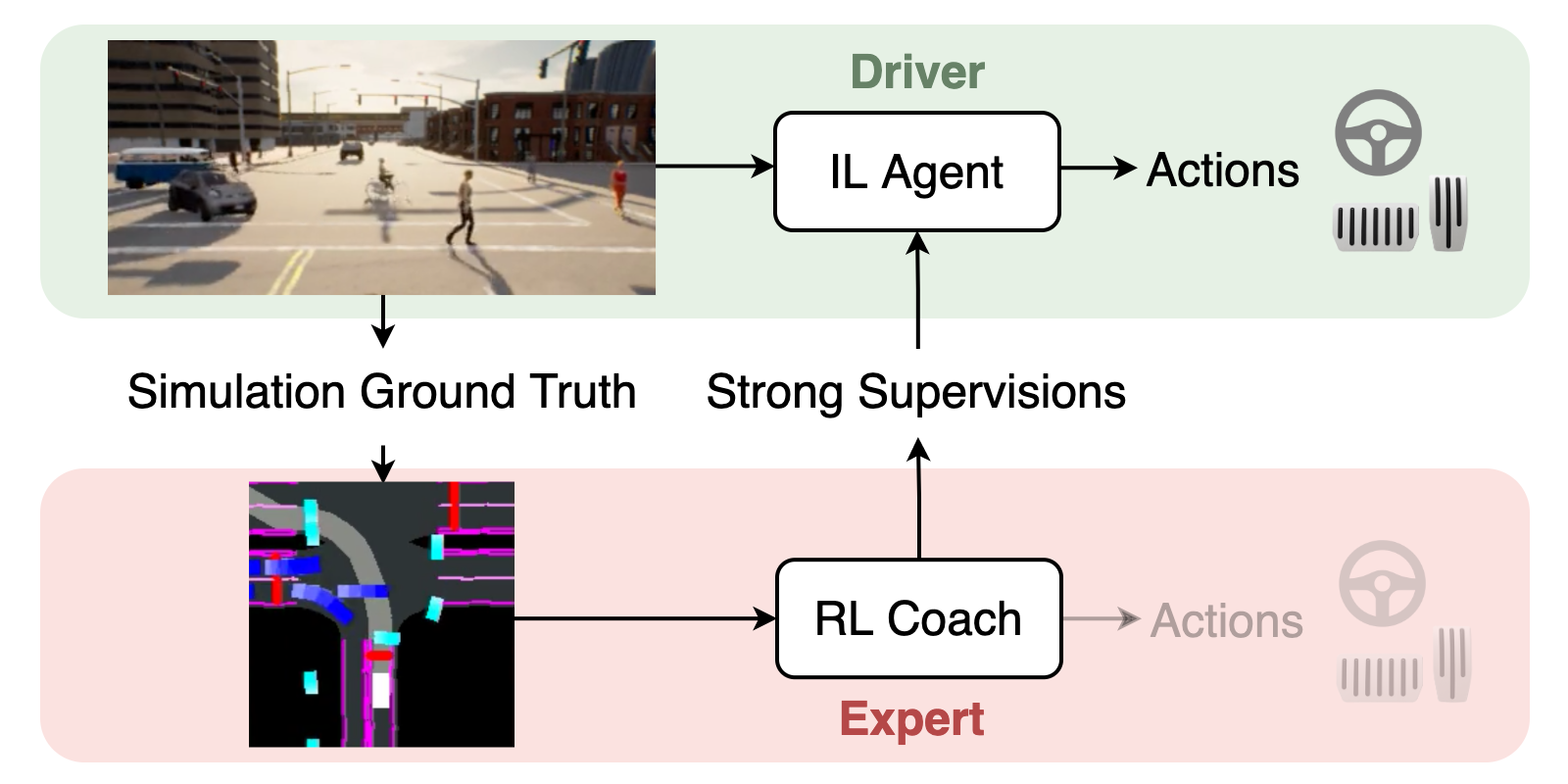
End-to-end approaches to autonomous driving commonly rely on expert demonstrations. Although humans are good drivers, they are not good coaches for end-to-end algorithms that demand dense on-policy supervision. On the contrary, automated experts that leverage privileged information can efficiently generate large scale on-policy and off-policy demonstrations. However, existing automated experts for urban driving make heavy use of hand-crafted rules and perform suboptimally even on driving simulators, where ground-truth information is available. To address these issues, we train a reinforcement learning expert that maps bird’s-eye view images to continuous low-level actions. While setting a new performance upper-bound on CARLA, our expert is also a better coach that provides informative supervision signals for imitation learning agents to learn from. Supervised by our reinforcement learning coach, a baseline end-to-end agent with monocular camera-input achieves expert-level performance. Our end-to-end agent achieves a 78% success rate while generalizing to a new town and new weather on the NoCrash-dense benchmark and state-of-the-art performance on the more challenging CARLA LeaderBoard.
ICCV 2021 Presentation
Result Videos
Highlights: IL Agent Supervised by Roach Diving with single camera image as input.
Unedited: Roach Driving with bird’s-eye-view image as input.
Unedited: Autopilot Driving with ground-truth information as input.
Paper
 | Zhejun Zhang, Alexander Liniger, Dengxin Dai, Fisher Yu, Luc Van Gool End-to-End Urban Driving by Imitating a Reinforcement Learning Coach ICCV 2021 |
Code

github.com/zhejz/carla-roach
Citation
@inproceedings{zhang2021roach,
title = {End-to-End Urban Driving by Imitating a Reinforcement Learning Coach},
booktitle = {Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV)},
author = {Zhang, Zhejun and Liniger, Alexander and Dai, Dengxin and Yu, Fisher and Van Gool, Luc},
year = {2021},
}