Abstract
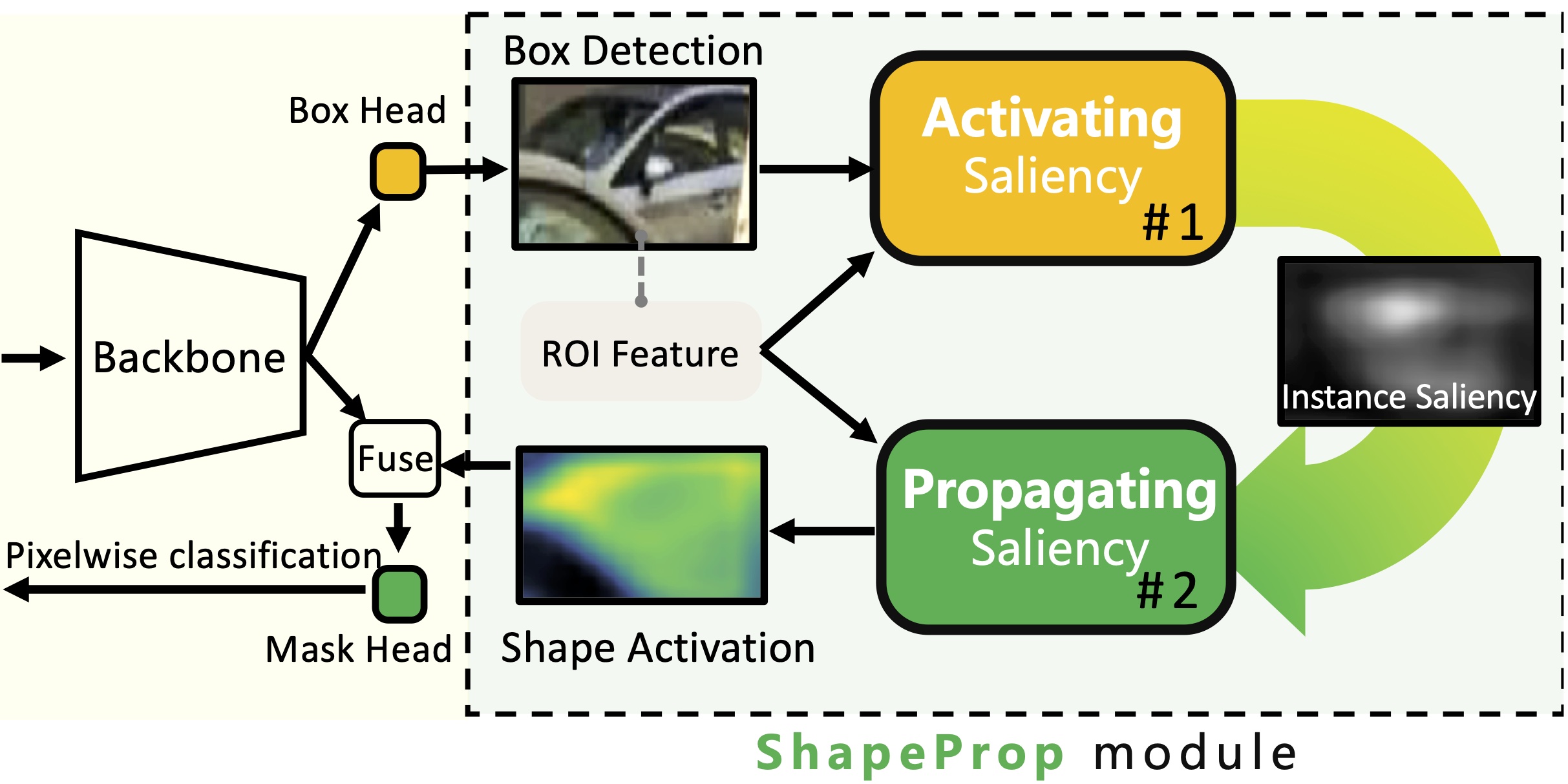
Instance segmentation is a challenging task for both modeling and annotation. Due to the high annotation cost, modeling becomes more difficult because of the limited amount of supervision. We aim to improve the accuracy of the existing instance segmentation models by utilizing a large amount of detection supervision. We propose ShapeProp, which learns to activate the salient regions within the object detection and propagate the areas to the whole instance through an iterative learnable message passing module. ShapeProp can benefit from more bounding box supervision to locate the instances more accurately and utilize the feature activations from the larger number of instances to achieve more accurate segmentation. We extensively evaluate ShapeProp on three datasets (MS COCO, PASCAL VOC, and BDD100k) with different supervision setups based on both two-stage (Mask R-CNN) and single-stage (RetinaMask) models. The results show our method establishes new states of the art for semi-supervised instance segmentation.
Paper
 | Yanzhao Zhou, Xin Wang, Jianbin Jiao, Trevor Darrell, Fisher Yu Learning Saliency Propagation for Semi-Supervised Instance Segmentation CVPR 2020 |
Code

github.com/ucbdrive/ShapeProp
Citation
@inproceedings{zhou2020learning,
title={Learning saliency propagation for semi-supervised instance segmentation},
author={Zhou, Yanzhao and Wang, Xin and Jiao, Jianbin and Darrell, Trevor and Yu, Fisher},
booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},
pages={10307--10316},
year={2020}
}