Abstract
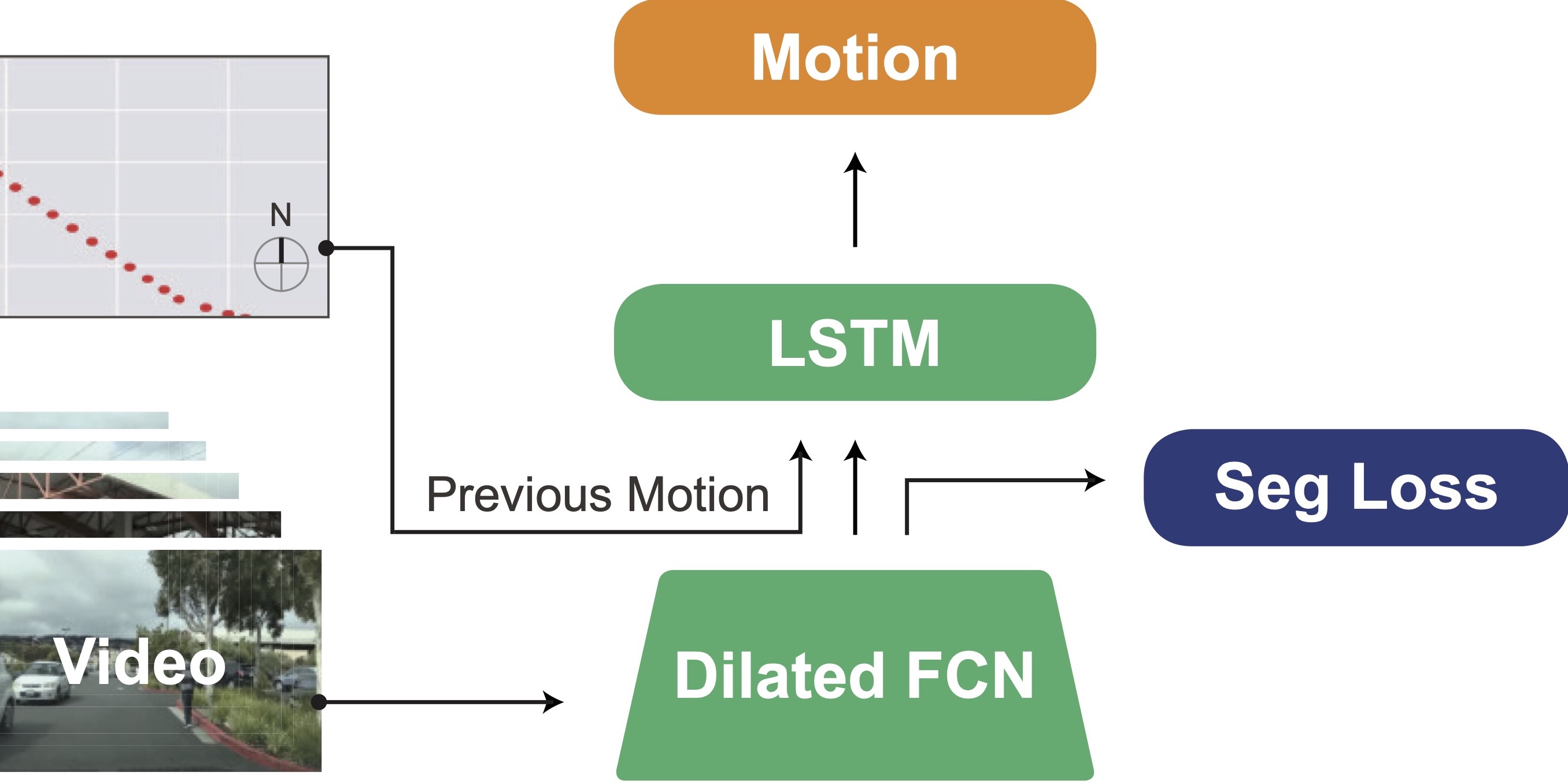
Visual anticipation of ego and object motion over a short time horizons is a key feature of human-level performance in complex environments. We propose a driving policy learning framework that predicts feature representations of future visual inputs; our predictive model infers not only future events but also semantics, which provide a visual explanation of policy decisions. Our Semantic Predictive Control (SPC) framework predicts future semantic segmentation and events by aggregating multi-scale feature maps. A guidance model assists action selection and enables efficient sampling-based optimization. Experiments on multiple simulation environments show that networks which implement SPC can outperform existing model-based reinforcement learning algorithms in terms of data efficiency and total rewards while providing clear explanations for the policy’s behavior.
Video
Paper
 | Xinlei Pan, Xiangyu Chen, Qizhi Cai, John Canny, Fisher Yu Semantic Predictive Control for Explainable and Efficient Policy Learning ICRA 2019 |
Code

github.com/ucbdrive/spc
Citation
@inproceedings{pan2019semantic,
title={Semantic predictive control for explainable and efficient policy learning},
author={Pan, Xinlei and Chen, Xiangyu and Cai, Qizhi and Canny, John and Yu, Fisher},
booktitle={2019 International Conference on Robotics and Automation (ICRA)},
pages={3203--3209},
year={2019},
organization={IEEE}
}