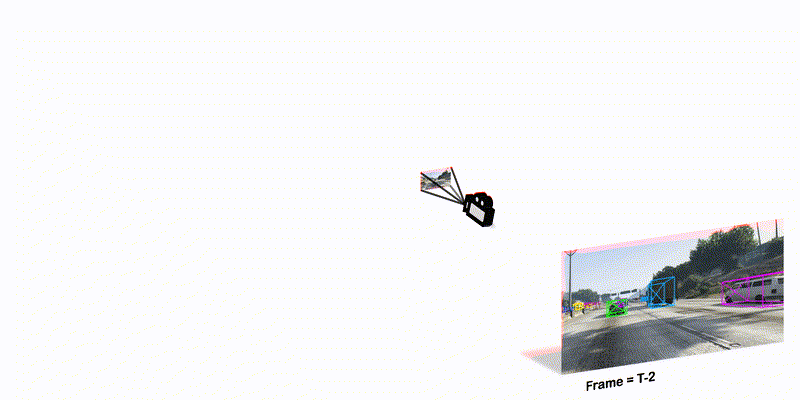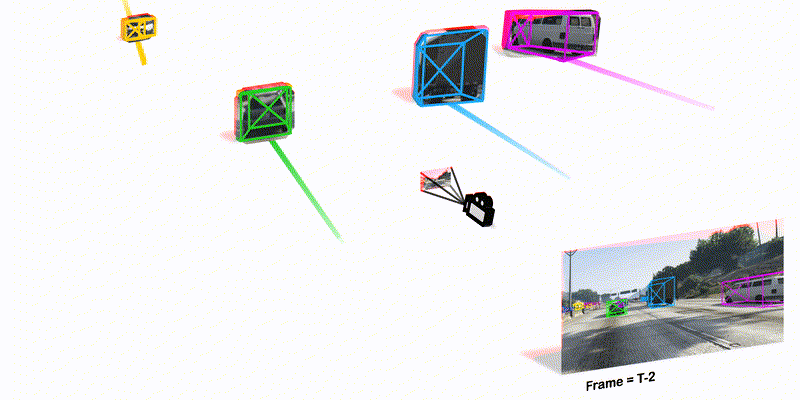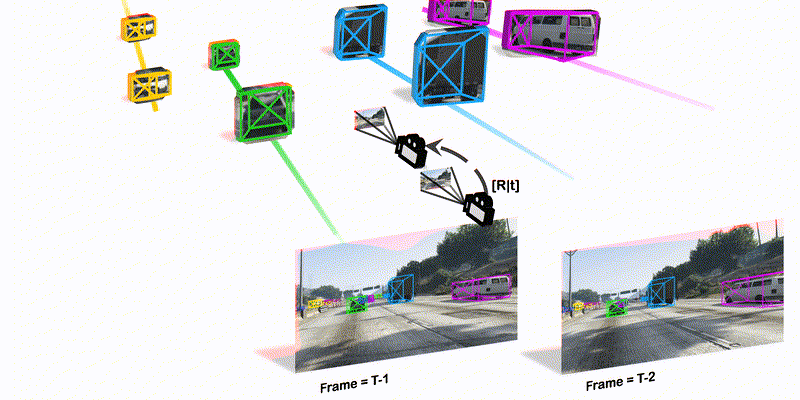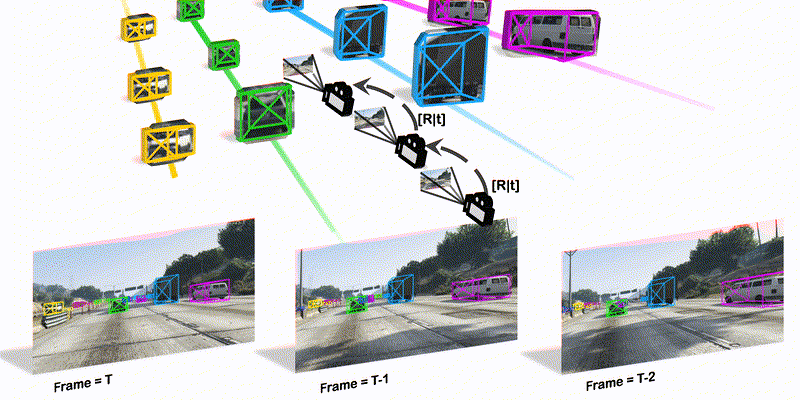
Abstract
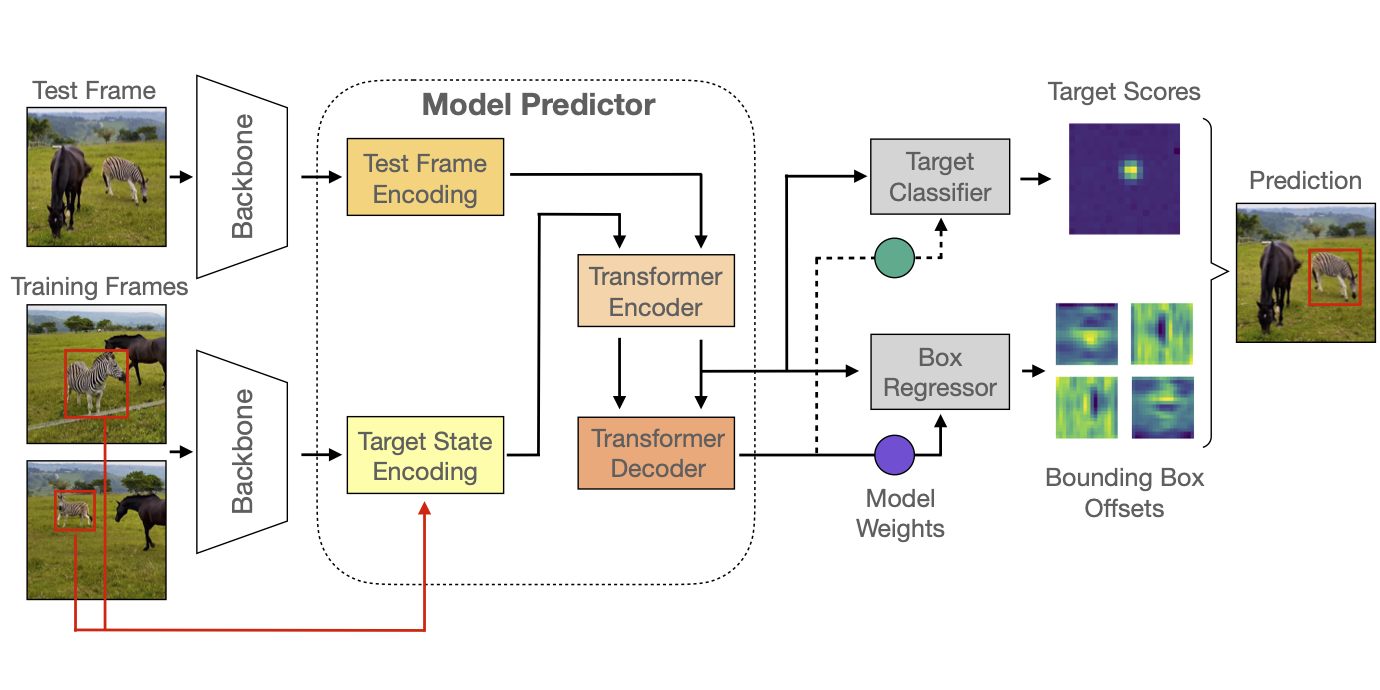
Optimization based tracking methods have been widely successful by integrating a target model prediction module, providing effective global reasoning by minimizing an objective function. While this inductive bias integrates valuable domain knowledge, it limits the expressivity of the tracking network. In this work, we therefore propose a tracker architecture employing a Transformer-based model prediction module. Transformers capture global relations with little inductive bias, allowing it to learn the prediction of more powerful target models. We further extend the model predictor to estimate a second set of weights that are applied for accurate bounding box regression. The resulting tracker relies on training and on test frame information in order to predict all weights transductively. We train the proposed tracker end-to-end and validate its performance by conducting comprehensive experiments on multiple tracking datasets. Our tracker sets a new state of the art on three benchmarks, achieving an AUC of 68.5% on the challenging LaSOT dataset.
Results
Paper
 | Christoph Mayer, Martin Danelljan, Goutam Bhat, Matthieu Paul, Danda Pani Paudel, Fisher Yu, Luc Van Gool Transforming Model Prediction for Tracking CVPR 2022 |
Code

github.com/visionml/pytracking
Citation
@inproceedings{mayer2022transforming,
author = {Mayer, Christoph and Danelljan, Martin and Bhat, Goutam and Paul, Matthieu and Paudel, Danda Pani and Yu, Fisher and Van Gool, Luc},
title = {Transforming Model Prediction for Tracking},
booktitle = {Computer Vision and Pattern Recognition},
year = {2022}
}