Abstract
While Video Instance Segmentation (VIS) has seen rapid progress, current approaches struggle to predict high-quality masks with accurate boundary details. Moreover, the predicted segmentations often fluctuate over time, suggesting that temporal consistency cues are neglected or not fully utilized. In this paper, we set out to tackle these issues, with the aim of achieving highly detailed and more temporally stable mask predictions for VIS.
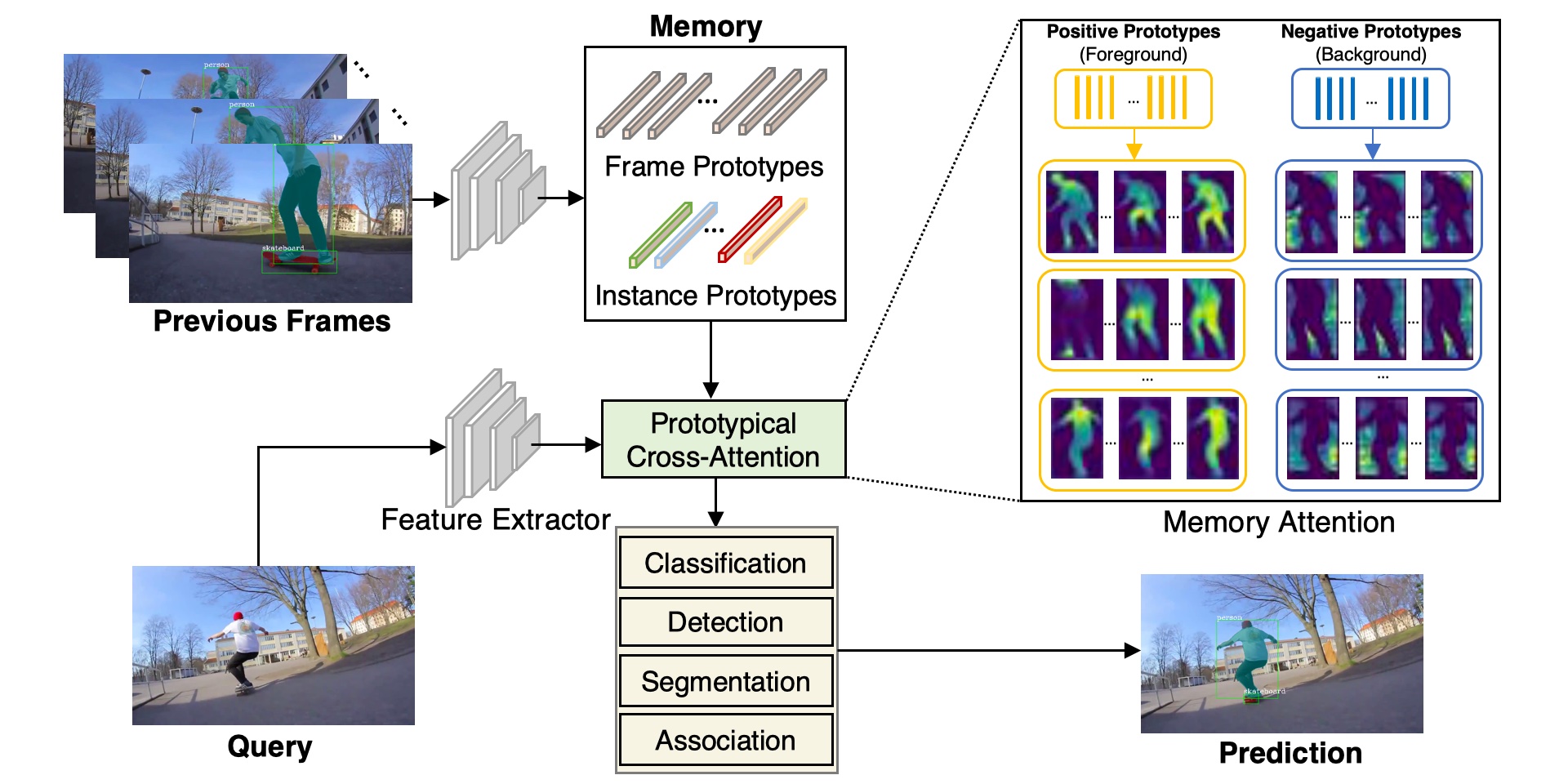
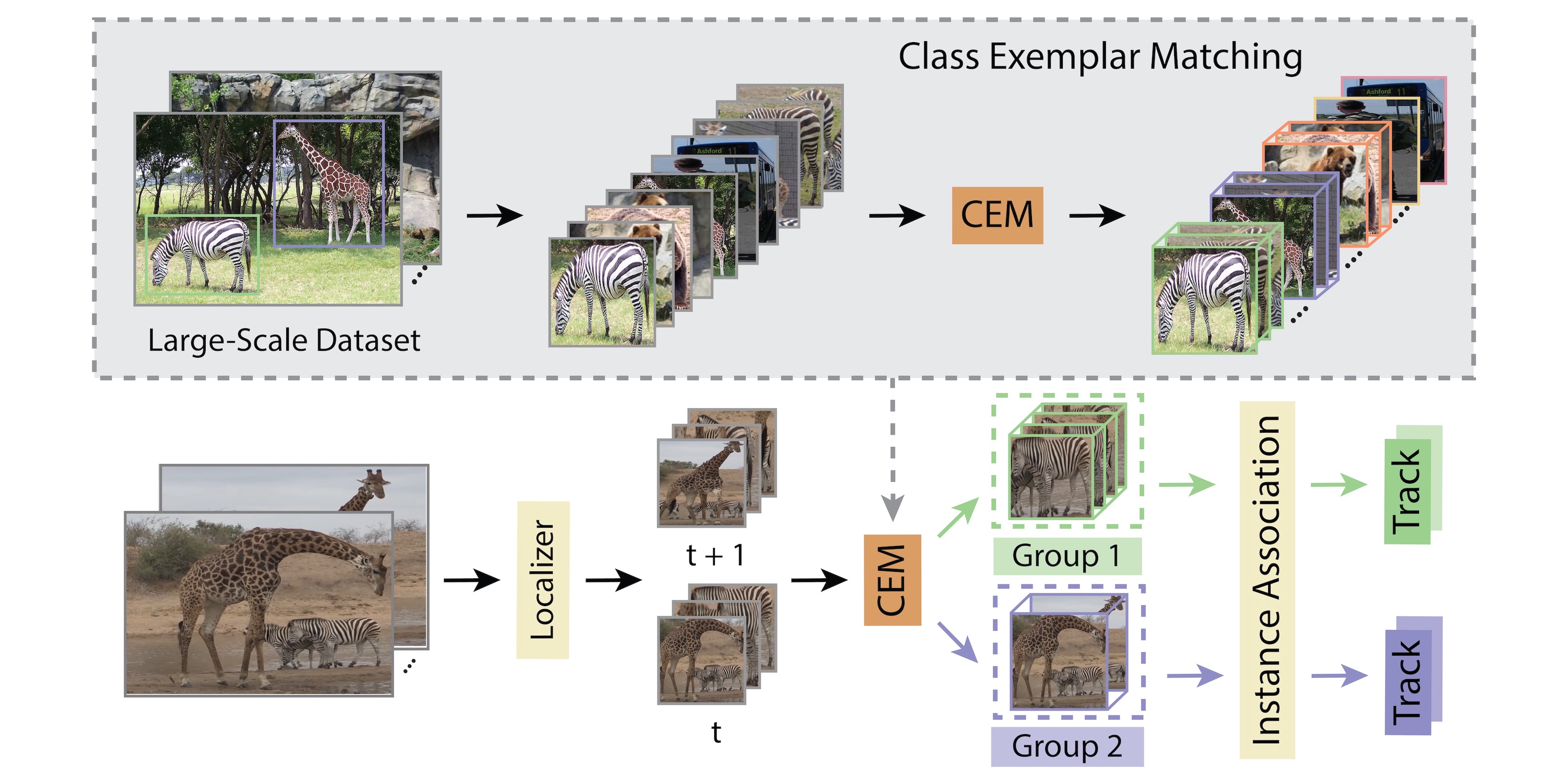
We first propose the Video Mask Transfiner (VMT) method, capable of leveraging fine-grained high-resolution features thanks to a highly efficient video transformer structure. Our VMT detects and groups sparse error-prone spatio-temporal regions of each tracklet in the video segment, which are then refined using both local and instance-level cues. Second, we identify that the coarse boundary annotations of the popular YouTube-VIS dataset constitute a major limiting factor.
Based on our VMT architecture, we therefore design an automated annotation refinement approach by iterative training and self-correction. To benchmark high-quality mask predictions for VIS, we introduce the HQ-YTVIS dataset, consisting of a manually re-annotated test set and our automatically refined training data. We compare VMT with the most recent state-of-the-art methods on the HQ-YTVIS, as well as the OVIS and BDD100K MOTS benchmarks. Experimental results clearly demonstrate the efficacy and effectiveness of our method on segmenting complex and dynamic objects, by capturing precise details.
Method

Visual Results Comparison
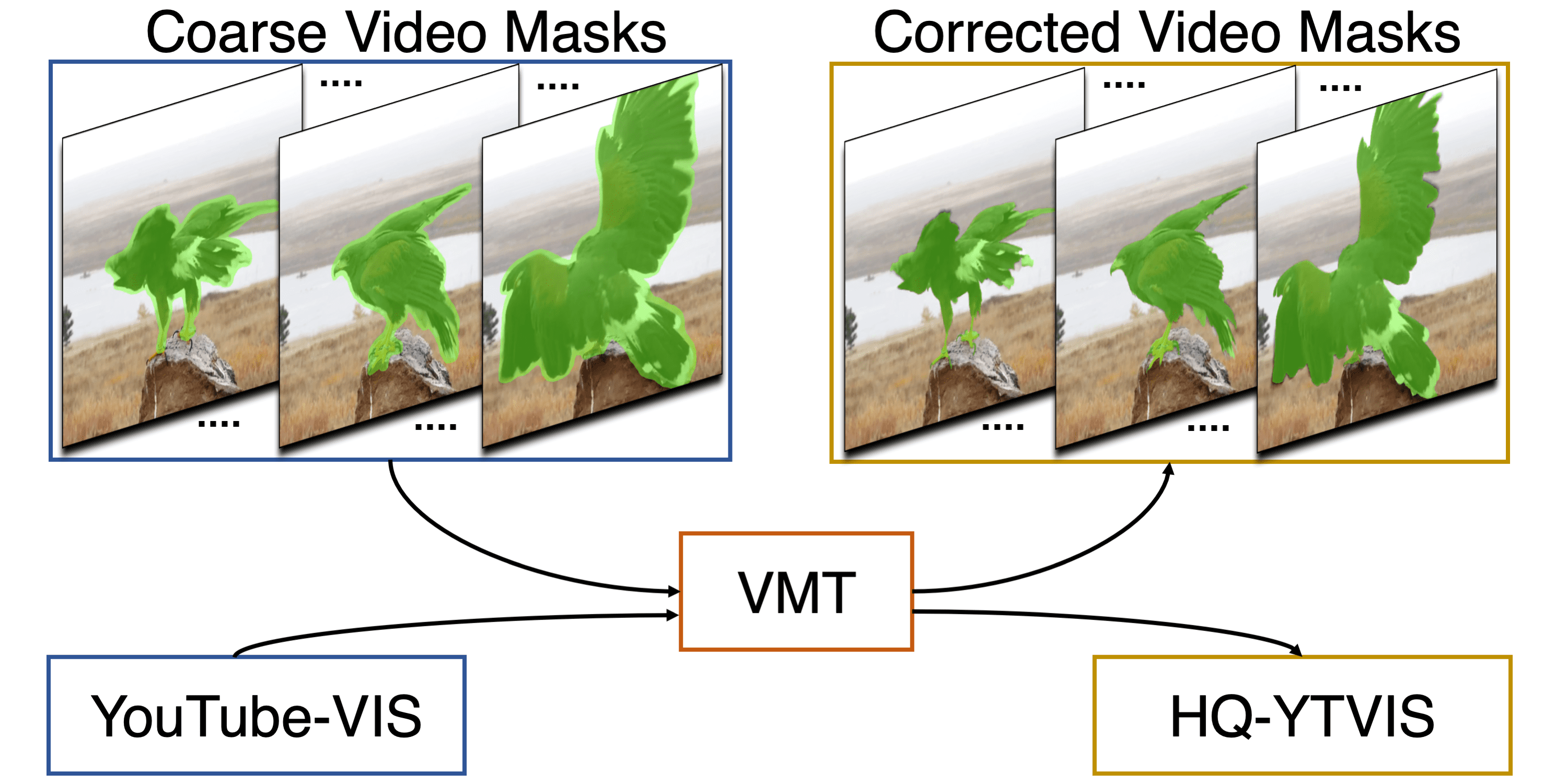
HQ-YTVIS vs. YTVIS
Based on our VMT architecture, we design an automated annotation refinement approach by iterative training and self-correction. To benchmark high-quality mask predictions for VIS, we introduce the HQ-YTVIS dataset and Tube-Boundary AP in ECCV 2022. Based on YTVIS, HQ-YTVIS consists of a manually re-annotated test set and automatically refined training data, which provides training, validation and testing support to facilitate future development of VIS methods aiming at higher mask quality.
 We only highlight the instance mask for one object per video for easy comparison. For more details on the HQ-YTVIS benchmark, please refer to the dataset page.
We only highlight the instance mask for one object per video for easy comparison. For more details on the HQ-YTVIS benchmark, please refer to the dataset page.
Paper
Please refer to our paper for more details of VMT and the HQ-YTVIS dataset.
 | Lei Ke, Henghui Ding, Martin Danelljan, Yu-Wing Tai, Chi-Keung Tang, Fisher Yu Video Mask Transfiner for High-Quality Video Instance Segmentation ECCV 2022 |
Code
The code and models of the VMT method, and our Tube-Boundary AP evaluation:

github.com/SysCV/vmt
License
HQ-YTVIS labels are provided under CC BY-SA 4.0 License. Please refer to YouTube-VOS terms for use of the videos.
Citation
@inproceedings{vmt,
title = {Video Mask Transfiner for High-Quality Video Instance Segmentation},
author = {Ke, Lei and Ding, Henghui and Danelljan, Martin and Tai, Yu-Wing and Tang, Chi-Keung and Yu, Fisher},
booktitle = {European Conference on Computer Vision (ECCV)},
year = {2022}
}