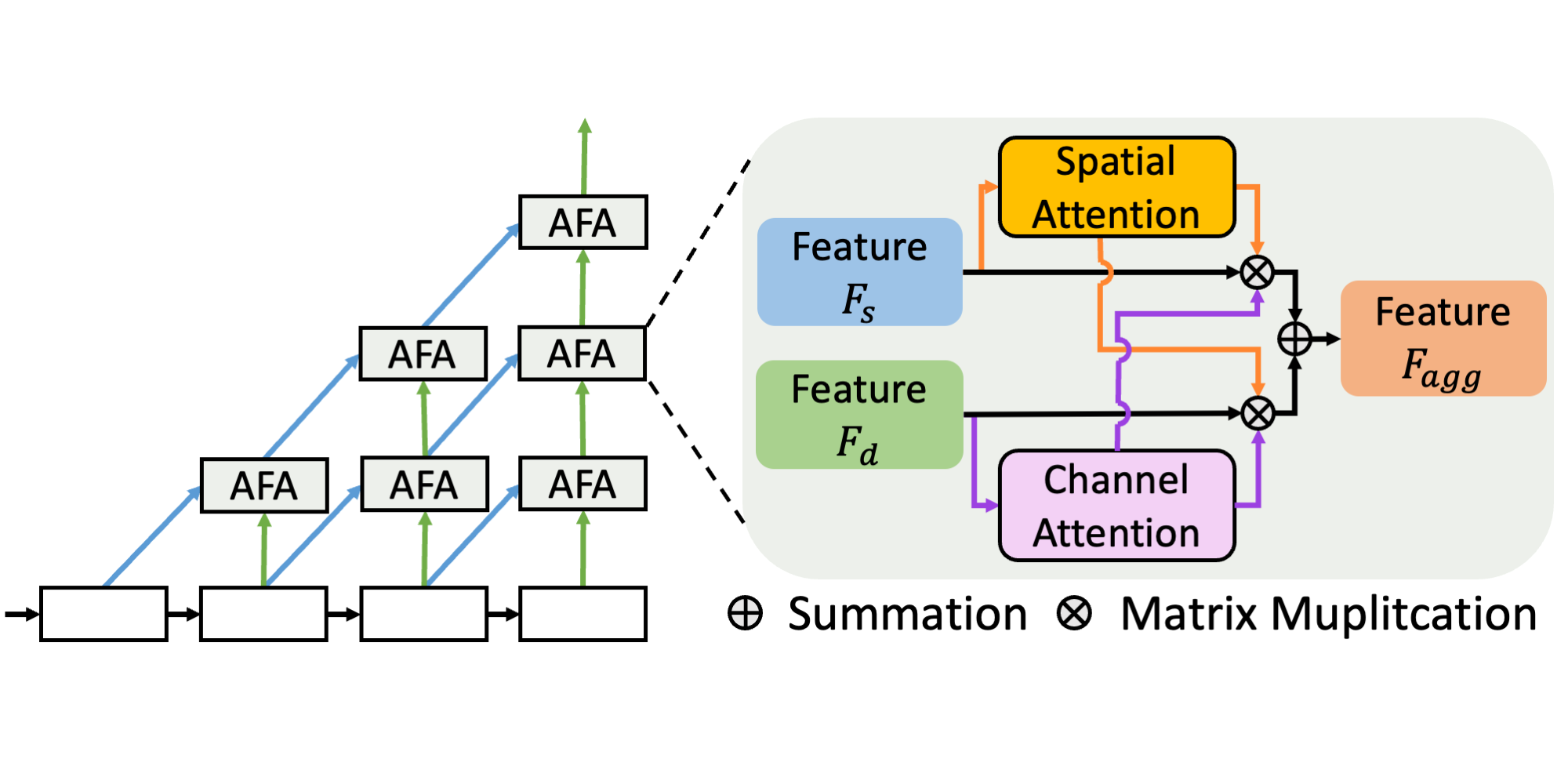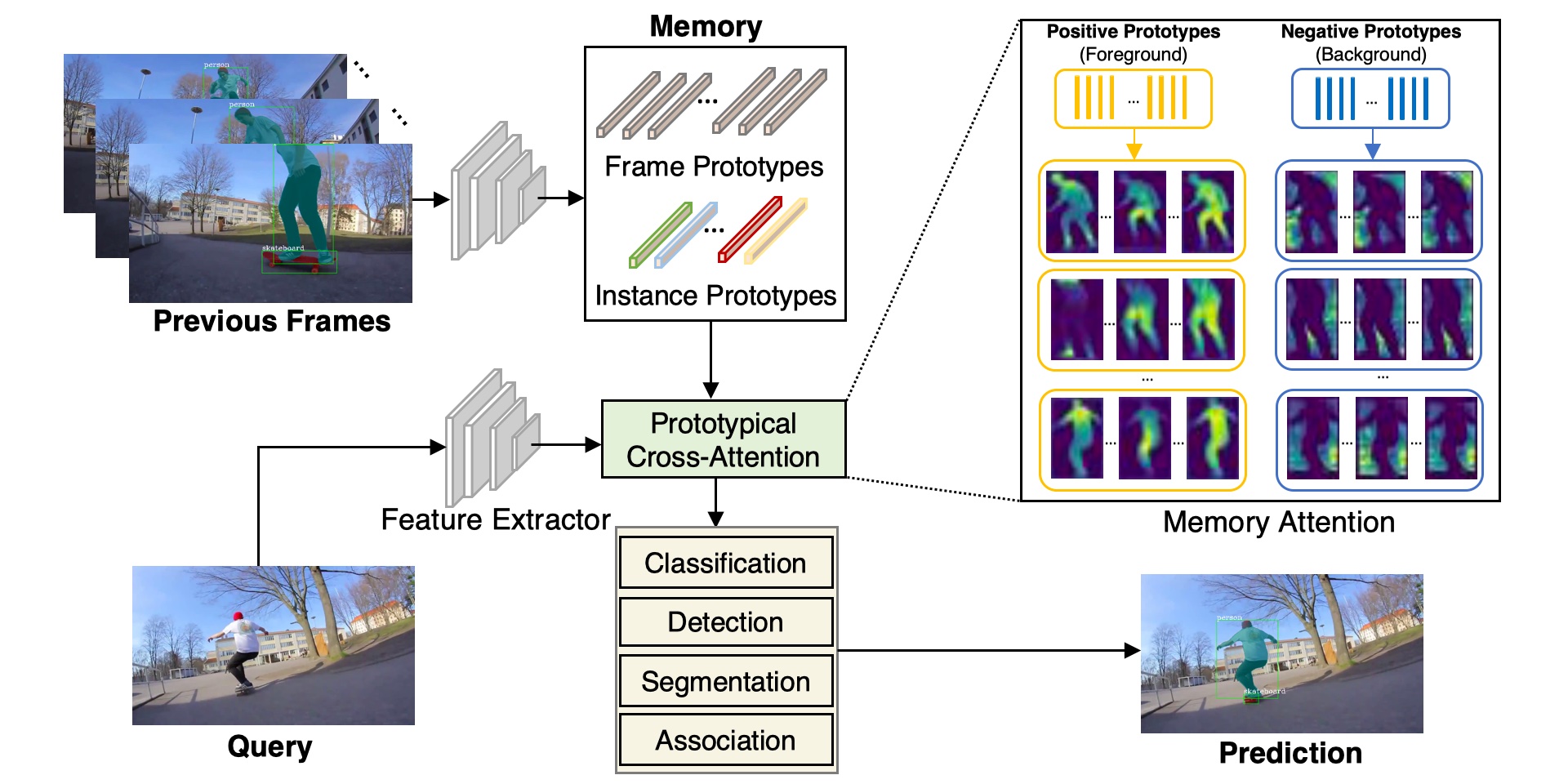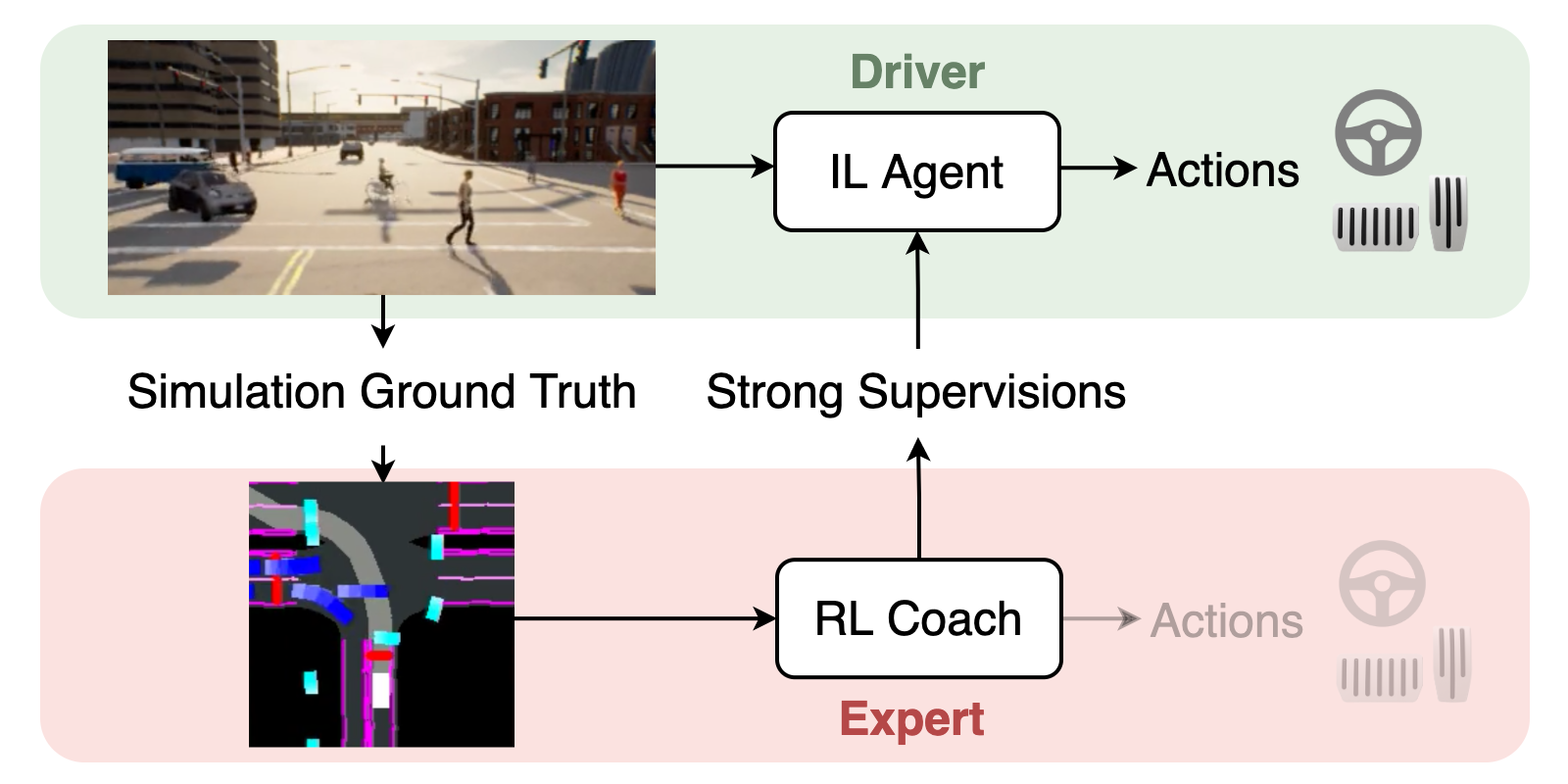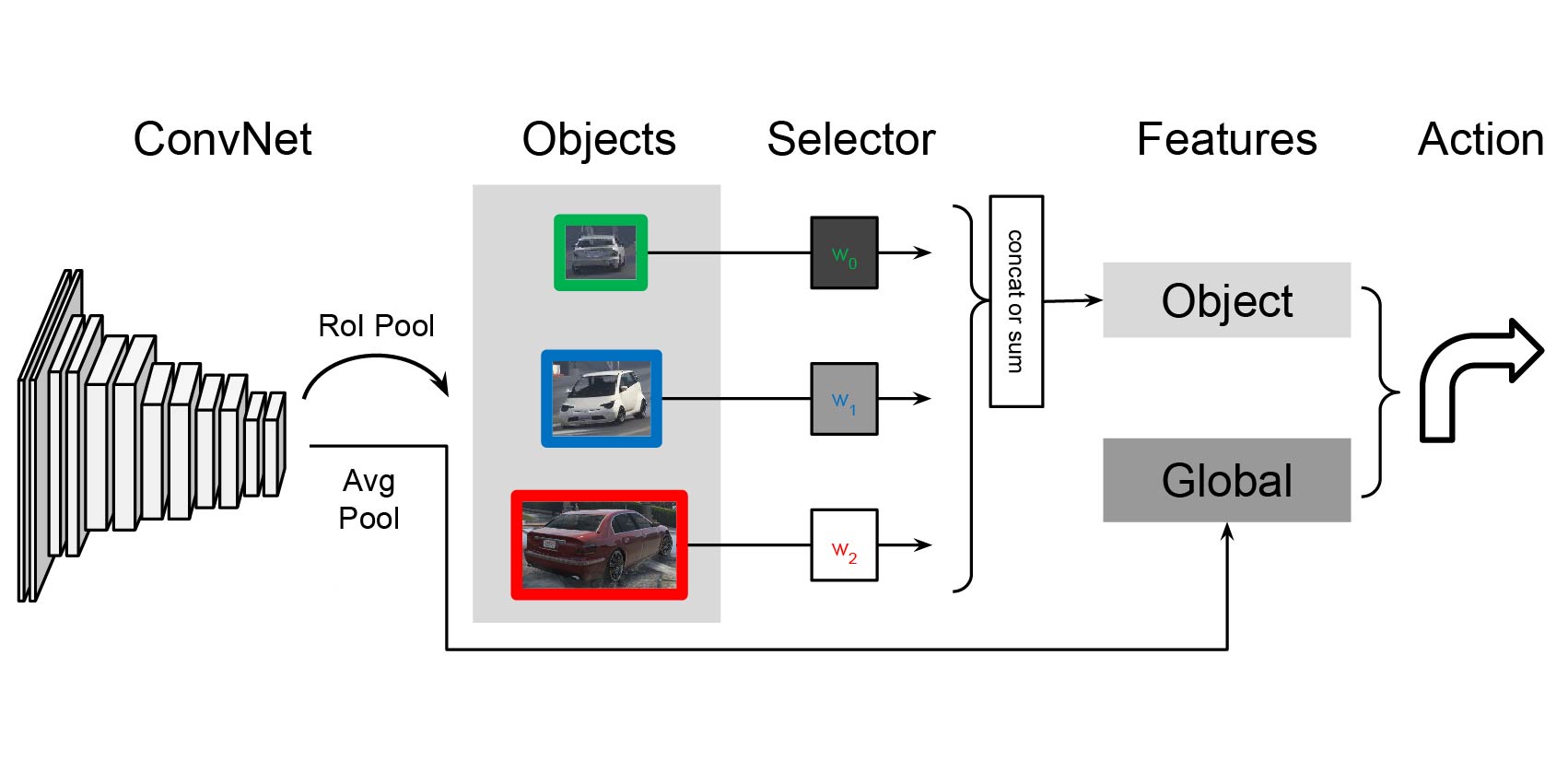
Abstract
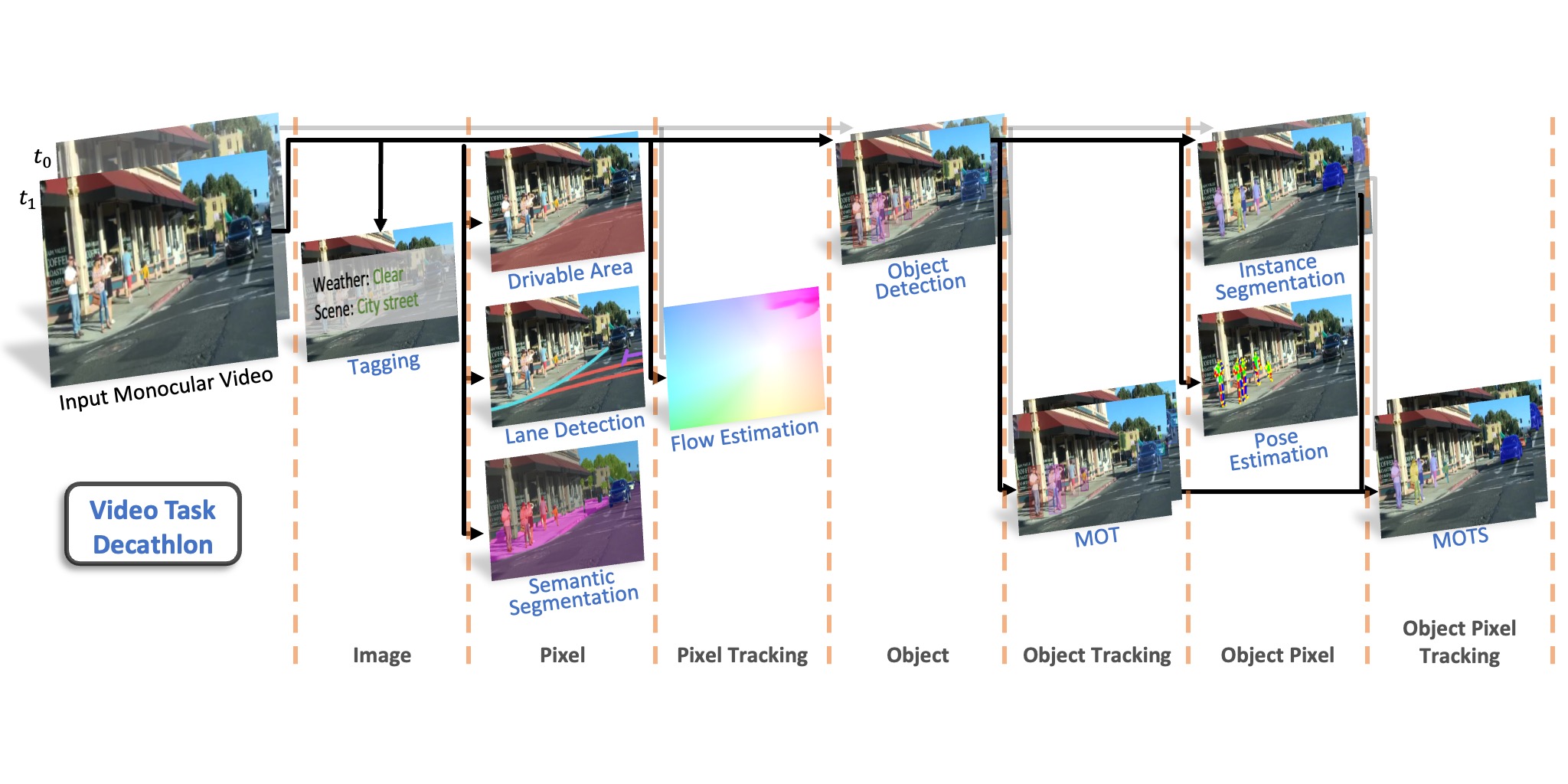
Performing multiple heterogeneous visual tasks in dynamic scenes is a hallmark of human perception capability. Despite remarkable progress in image and video recognition via representation learning, current research still focuses on designing specialized networks for singular, homogeneous, or simple combination of tasks. We instead explore the construction of a unified model for major image and video recognition tasks in autonomous driving with diverse input and output structures. To enable such an investigation, we design a new challenge, Video Task Decathlon (VTD), which includes ten representative image and video tasks spanning classification, segmentation, localization, and association of objects and pixels. On VTD, we develop our unified network, VTDNet, that uses a single structure and a single set of weights for all ten tasks. VTDNet groups similar tasks and employs task interaction stages to exchange information within and between task groups. Given the impracticality of labeling all tasks on all frames, and the performance degradation associated with joint training of many tasks, we design a Curriculum training, Pseudo-labeling, and Fine-tuning (CPF) scheme to successfully train VTDNet on all tasks and mitigate performance loss. Armed with CPF, VTDNet significantly outperforms its single-task counterparts on most tasks with only 20% overall computations. VTD is a promising new direction for exploring the unification of perception tasks in autonomous driving.
Paper
 | Thomas E. Huang, Yifan Liu, Luc Van Gool, Fisher Yu Video Task Decathlon: Unifying Image and Video Tasks in Autonomous Driving ICCV 2023 |
Code

github.com/SysCV/vtd (coming soon)
Citation
@inproceedings{huang2023vtd,
title={Video Task Decathlon: Unifying Image and Video Tasks in Autonomous Driving},
author={Huang, Thomas E and Liu, Yifan and Van Gool, Luc and Yu, Fisher},
journal={International Conference on Computer Vision (ICCV)},
year={2023}
}